
基于YOLOv5的中式快餐店菜品识别系统[金鹰物联智慧食堂项目]
摘要
本文基于YOLOv5v6.1提出了一套适用于中式快餐店的菜品识别自助支付系统,综述了食品识别领域的发展现状,简要介绍了YOLOv5模型的历史背景、发展优势和网络结构。在数据集预处理过程中,通过解析UNIMIB2016,构建了一套行之有效的标签格式转换与校验流程,解决了YOLOv5中文件路径问题、标签格式转换问题和因EXIF信息的存在而导致的标记错位问题。在模型训练阶段,配置了云服务器,引入了Weights and Bias可视化工具,实现了在线监督训练和sweep超参数调优的功能,在sweep中使用hyperband剪枝算法加速了sweep过程,并且给出了对于训练过程中可能出现的问题的解决方法。最后介绍了目标识别领域的评价指标和YOLOv5的损失函数,分析了sweep超参数调优的结果,选取最优参数组合训练模型,通过分析样本分布、PR曲线等,选取最佳预测置信度,大幅提升了预测精度和召回率,部署了模型并制作了客户端。
引言
随着智能信息化时代的到来,人工智能与传感技术取得了巨大进步,在智能交通、智能家居、智能医疗等民生领域产生积极正面影响。其中,社交网络、移动网络和物联网等新兴技术产生了食品大数据,这些大数据与人工智能,尤其是快速发展的深度学习催生了新的交叉研究领域食品计算。现在,在智慧健康、食品智能装备、智慧餐饮、智能零售及智能家居等方面都可以找到食品大数据与人工智能相结合的例子。
人工智能时代下的食品图像识别是当前计算机视觉研究的重要领域之一。我们希望研发一种可快速且高效识别菜品的校园菜肴识别系统,在校园食堂中应用本系统,可缩短收银员计算价格的时间、简化收银步骤;可协助管理者精准备餐、减少库存的浪费;就餐者还可以即时看见摄入的食物营养价值,实现膳食平衡;另外,可迅速实现食品的安全溯源,避免出现食品安全情况。
传统的食物图像识别方法是选择图像特征,然后使用某些方法(比如SIFT、HOG)提取图像特征点,再将特征点用矢量表示,最后采用机器学习的方法训练分类器(如SVM、K-Means)。传统食物图像识别提取特定特征或者关键点对食物进行分类,但在实际应用中,拍摄的图像会受到环境的光照强度、噪声干扰、环境光等外部因素的干扰,导致拍摄图像质量参差,从而影响最终的检测结果同一事物的颜色形状会有差异,不同食物直接的颜色形状也会相同。所以传统的图像识别方法很难准确识别出食物。
深度学习的发展使得当前大部分工作均采用卷积神经网络,思路是先对菜品图像中不同的菜品区域进行检测或分割,然后对其区域进行识别。从2014年开始,基于深度学习的目标检测网络井喷式爆发,先是二阶段网络,如R-CNN、Fast-RCNN、Mask-RCNN等,自2016年Joseph等提出You only Look Once(YOLOv1)以来学者者们的视野,开启了单阶段目标检测网络的新纪元。YOLO均是对单阶段目标检测模型改进的研究,为各研究领域提供了更快、更好的目标检测方法,也为单阶段目标检测算法的实际应用提供了重要理论保障。例如 Aguilar 等人微调物体检测算法 YOLOv2 来进行多种食物检测和识别。又如 Pandey 等人微调了 AlexNet、GoogLeNet、ResNet等三种CNN网络,然后基于微调的网络提取和融合来自不同网络的视觉特征,通过集成学习方法实现菜品图像识别。随着深度学习的发展,卷积神经网络(CNN)在各领域中获得不俗的效果,菜品识别也围绕卷积神经网络展开研究,不仅提出了新的方法,也提升了检测精度。
2020 年 6 月 10 日 YOLOv5 发布,随着版本迭代更新,其已成为现今最先进的目标检测技术之一。YOLOv5 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集;能够直接对视频甚至网络摄像头端口输入进行有效推理,有着高达140FPS的目标识别速度;能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,或者通过CoreML转化为IOS格式,以便直接部署到手机应用端。
YOLO的核心思想就是将整张图片作为网络的输入,利用“分而治之”的思想,对图片进行网格划分,直接在输出层回归边界框的检测位置及其所属的类别。与Faster R-CNN相比,YOLO产生的背景错误要少得多。通过使用YOLO来消除Faster RCNN的背景检测,可以显着提高模型性能。实验表明YOLO v5可以达到比Faster R-CNN更快的收敛速度,并且在小目标的检测上比SSD模型更加准确。
数据集
数据集来源和说明
本文所使用的托盘食物数据集来源于 UNIMIB2016 Food Database. 此数据集在真实餐厅环境中收集而来,每张照片的尺寸为 (3264, 2448),包含一个托盘和托盘上不同的食物,有些食物放在餐具垫上而非碟子中。有时,多种菜会被放置在同一碟子中,这给图像分割带来了困难。此外,图像畸变和光线环境等影响也会给分割和识别带来挑战。
The dataset has been collected in a real canteen environment. The particularities of this setting are that each image depicts different foods on a tray, and some foods (e.g. fruit, bread and dessert) are placed on the placemats rather than on plates. Sides are often served in the same plate as the main dish making it difficulty to separate the two. Moreover, the acquisition of the images has been performed in a semi-controlled settings so the images present visual distortions as well as illumination changes due to shadows. These characteristics make this dataset challenging requiring both the segmentation of the trays for food localization, and a robust way to deal with multiple foods.


如图3所示,在数据集中,许多类别的食物非常相似,例如,有四种不同的“Pasta al sugo”,其中添加了其他主要成分(如鱼肉、蔬菜或者其他的一些肉类)。最后,托盘上可能有其他物品造成干扰,比如有智能手机、钱包、校园卡等等。
Figure 3, many food classes have a very similar appearance. For example, we have four different “Pasta al sugo”, but with other main ingredients (e.g. fish, vegetables, or meat) added. Finally, on the tray there can be other “noisy” objects that must be ignored during the recognition. For example, we may find cell phones, wallets, id cards, and other personal items. For these reasons we need to design of a very accurate recognition algorithm.

数据集处理
作者团队一共收集了1442张照片,去除模糊和重复照片后,将剩余有效图片保存在UNIMIB2016-images中。其中,包含1027张照片,共计73种菜品,总计3616个菜品实例。一些种类的食物只是在成分上有所不同,所以命名为“FoodName 1”, “FoodName 2”.
接下来,处理UNIMIB2016-annotations.zip中的annotations.mat文件,将其转换为yolo格式。
在UNIMIB2016-annotations中,存有annotations.mat标记文件,.mat文件是Matlab的Map对象(Map object),其介绍如下:
A
Mapobject is a data structure that allows you to retrieve values using a corresponding key. Keys can be real numbers or character vectors. As a result, they provide more flexibility for data access than array indices, which must be positive integers. Values can be scalar or nonscalar arrays.
MAT文件解析
若使用scipy.io.loadmat工具解析.mat文件,如需要加载annotations.mat,在Map object多级嵌套时,解析可能出现意想不到的错误,故编写Matlab脚本将annotations.mat文件解析为YOLOv5所需的标记文件格式。
% .
% ├── annotations.mat
% ├── demo.m
% ├── formatted_annotations
% │ ├── 20151127_114556.txt
% │ ├── 20151127_114946.txt
% │ ├── 20151127_115133.txt
% │ ├── ...
% │ └── 20151221_135642.txt
% └── load_annotations.m
%% load_annotations.m
clc; clear;
% output path
output = './formatted_annotations/';
% Load the annotations in a map structure
load('annotations.mat');
% Each entry in the map corresponds to the annotations of an image.
% Each entry contains many cell tuples as annotated food
% A tuple is composed of 8 cells with the annotated:
% - (1) item category (food for all tuples)
% - (2) item class (e.g. pasta, patate, ...)
% - (3) item name
% - (4) boundary type (polygonal for all tuples)
% - (5) item's boundary points [x1,y1,x2,y2,...,xn,yn]
% - (6) item's bounding box [x1,y1,x2,y2,x3,y3,x4,y4]
image_names = annotations.keys;
n_images = numel(image_names);
for j = 1 : n_images
image_name = image_names{j};
tuples = annotations(image_name);
count = size(tuples,1);
coordinate_mat = cell2mat(tuples(:,6));
% open file
file_path = [output image_name '.txt'];
ffile = fopen(file_path, 'w');
% write file
for k = 1 : count
item = tuples(k,:);
fprintf(ffile, '%s %d %d %d %d %d %d %d %dn', ...
string(item(2)), ... % item class
coordinate_mat(k,:)); % item's bounding box
end
% close file
fclose(ffile);
end
%% fprintf
% Write data to text file
% https://www.mathworks.com/help/matlab/ref/fprintf.html
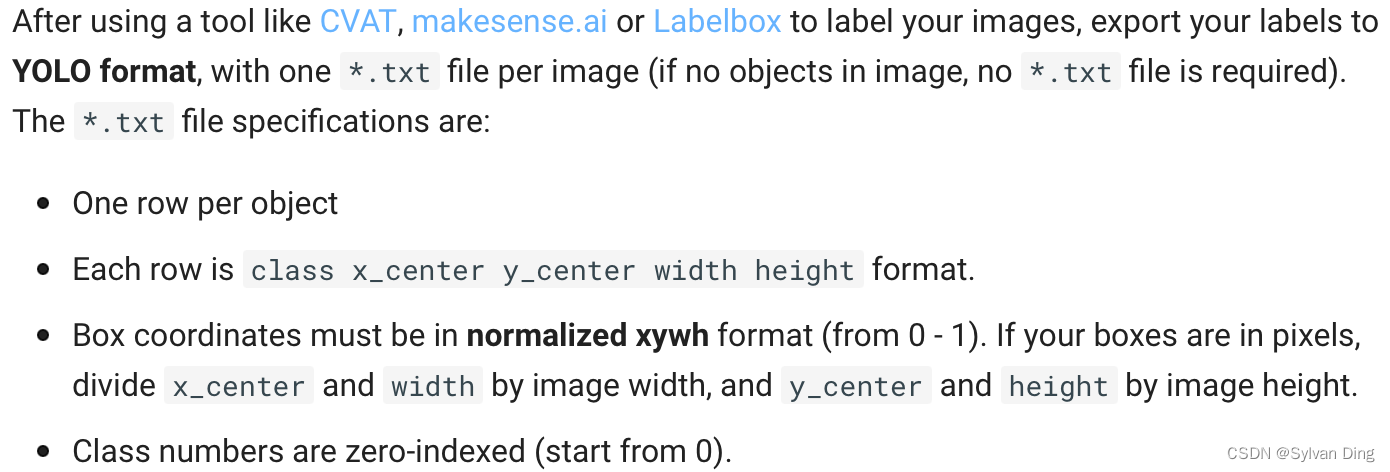
运行上述Matlab脚本文件,在./formatted_annotations文件夹下生成以图片名命名的*.txt文件,每一行的格式为class x1 y1 x2 y2 x3 y3 x4 y4.

bounding box如图所示:(xy1左上,xy3右下)

数据集有效性检验
下载并解压 [UNIMIB2016-images.zip],./original文件夹内为所有图片数据。将 original文件夹重命名为images,今后该文件夹用来存放图片数据,否则YOLOv5模型训练会发生错误,具体原因请看 一文彻底解决YOLOv5训练找不到标签问题。编写check_dataset.py,检查formatted_annotations中标签文件是否和images中图像文件一一对应,删除无效的标签和不匹配的标签。
# UNIMIB2016
# ├── UNIMIB2016-annotations
# │ ├── check_dataset.py <--
# │ └── formatted_annotations
# └── images
# check_dataset.py
import os
# path of formatted_annotations
f_path = os.path.join(os.getcwd(), 'formatted_annotations')
# path of images
img_path = os.path.join(os.getcwd(), os.pardir, 'images')
def check_dataset():
annotations = [i[:-4] for i in os.listdir(f_path)]
imgs = [i[:-4] for i in os.listdir(img_path)]
for annotation in annotations:
label = annotation + '.txt'
label_path = os.path.join(f_path, label)
try:
if annotation not in imgs:
# remove annotation which is not in images
print('not found image: {}, remove its annotation'.format(annotation))
print(label_path)
raise FileExistsError
else:
# check extra spaces in a line
with open(label_path) as f:
lines = f.readlines()
for line in lines:
item = line.split()
if len(item) > 9:
print('wrong label format: {}, {}'.format(annotation, line))
raise FileExistsError
except FileExistsError:
os.remove(label_path)
print('os.remove({})'.format(label_path))
if __name__ == '__main__':
check_dataset()
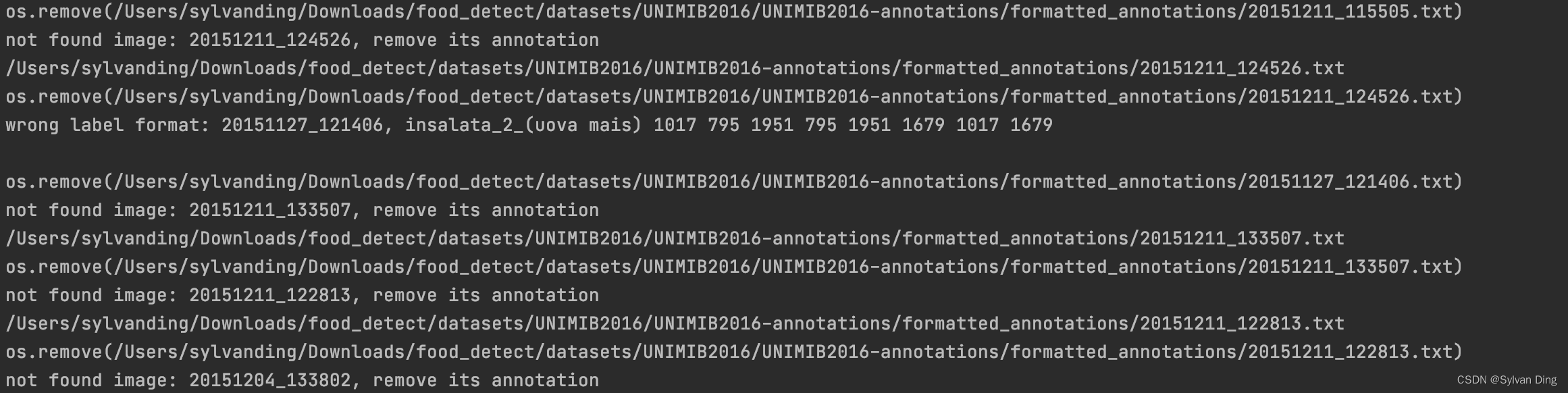
部分输出如下,check_dataset.py检查出21份在images中找不到对应图片的*.txt标记文件,检查出1份在类别标签中含有空格的*.txt标记文件,剔除这22份无效标记文件后,formatted_annotations中还剩余1005份有效标记文件。
食物类别统计
编写class_count.py,生成formatted_annotations中所有食品种类的统计数据:
# UNIMIB2016
# ├── UNIMIB2016-annotations
# │ ├── check_dataset.py
# │ ├── class_count.py <--
# │ └── formatted_annotations
# └── images
# class_count.py
import os
import pandas as pd
# formatted_annotations path
path = os.path.join(os.getcwd(), 'formatted_annotations')
# output path
output = os.path.join(os.getcwd(), 'class_counts_result.csv')
# read file list of formatted_annotations
annotations = os.listdir(path)
if __name__ == '__main__':
labels = []
for annotation in annotations:
with open(os.path.join(path, annotation)) as file:
for line in file:
item = line.split()
cls = item[0]
labels.append(cls)
counts = pd.Series(labels).value_counts()
counts.to_csv(output, header=False)
分类统计结果存于class_counts_result.csv. 部分统计数据如下:(未进行上一目有前性检验前共73个分类),按出现次数从高到低,从0开始为每个分类进行编号。
| Class | Num |
|---|---|
| pane | 479 |
| mandarini | 198 |
| carote | 161 |
| patate/pure | 151 |
| cotoletta | 148 |
| fagiolini | 131 |
| yogurt | 130 |
标签格式转换
接下来编写python脚本,将这些数据转换为YOLOv5所需格式:
编写toYolo.py,将formatted_annotations中所有*.txt转换为Yolo格式,将生成的结果存于labels中。
# UNIMIB2016
# ├── UNIMIB2016-annotations
# │ ├── check_dataset.py
# │ ├── class_count.py
# │ ├── toYolo.py <--
# │ ├── class_counts_result.csv
# │ └── formatted_annotations (1005)
# ├── labels
# └── images (1005)
# toYolo.py
import os
from PIL import Image
# formatted_annotations path
path = os.path.join(os.getcwd(), 'formatted_annotations')
# path of images
img_path = os.path.join(os.getcwd(), os.pardir, 'images')
# output path
output_path = os.path.join(os.getcwd(), os.pardir, 'labels')
# class count file path
class_file_path = os.path.join(os.getcwd(), 'class_counts_result.csv')
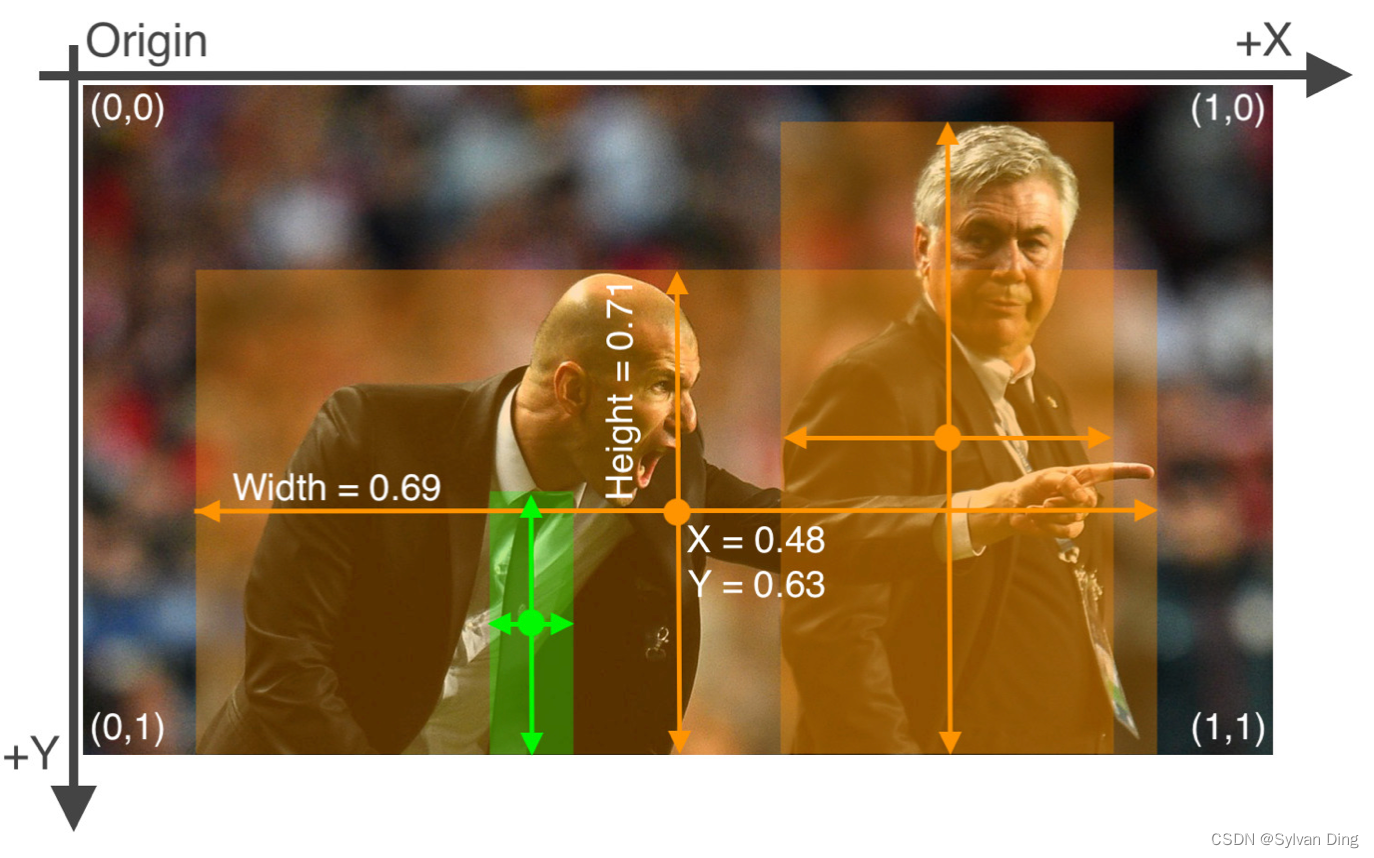
def convert_box(size, box):
# convert VOC to yolo format
dw, dh = 1. / size[0], 1. / size[1]
x, y, w, h = (box[0] + box[1]) / 2.0, (box[2] + box[3]) / 2.0, box[1] - box[0], box[3] - box[2]
return [x * dw, y * dh, w * dw, h * dh]
def convert_bbox(ibb):
# convert ibb to VOC format
# ibb = [x1,y1,x2,y2,x3,y3,x4,y4]
X = ibb[0::2]
Y = ibb[1::2]
xmin = min(X)
ymin = min(Y)
xmax = max(X)
ymax = max(Y)
return xmin, ymin, xmax, ymax
def get_classes():
# output: class list
cf = open(class_file_path, 'r')
clss = [line.split(',')[0] for line in cf.readlines()]
cf.close()
return clss
def toYolo():
# read file list of formatted_annotations
annotations = os.listdir(path)
# get class list
clss = get_classes()
# convert every annotation in ./formatted_annotations/ to yolo format
for annotation in annotations:
with open(os.path.join(path, annotation)) as file, open(os.path.join(output_path, annotation), 'w') as opfile:
# read img
img_f_path = os.path.join(img_path, annotation[:-4] + '.jpg')
img = Image.open(img_f_path)
# get img size
size = img.size
# process every item in ./formatted_annotations/*.txt
for line in file:
item = line.split(' ')
# get class num
cls = item[0]
cls_num = clss.index(cls)
# get bbox coordinates
item_bounding_box = list(map(float, item[1:]))
xmin, ymin, xmax, ymax = convert_bbox(item_bounding_box)
b = [xmin, xmax, ymin, ymax]
bb = convert_box(size, b)
# append item to output file: ../labels/*.txt
item_str = list(map(str, [cls_num] + bb))
line_yolo = ' '.join(item_str)
opfile.write(line_yolo + 'n')
print(annotation)
if __name__ == '__main__':
toYolo()
数据集校验
图片修正
由于 EXIF Rotation Information 的存在,在 YOLOv5 使用的 cv2 读取图片时,对图片参考系的选取产生影响,导致labels偏离原图片,故需要对图片进行修正,具体原因请查阅 yolov5踩坑记录:标签错位(PIL读取图片方向异常)。
修正前(标记错位)

修正后

修正代码
# UNIMIB2016
# ├── UNIMIB2016-annotations
# │ ├── check_dataset.py
# │ ├── class_count.py
# │ ├── toYolo.py
# │ ├── class_counts_result.csv
# │ └── formatted_annotations
# ├── rectify_imgs.py <--
# ├── labels (1005)
# └── images (1005)
# rectify_imgs.py
import os
from PIL import Image
import numpy as np
# image type
img_type = '.jpg'
# image folder path
path = os.path.join(os.getcwd(), 'images')
def rectify_imgs():
for img_name in os.listdir(path):
if not img_name[-4:] == img_type:
continue
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img_rectified = Image.fromarray(np.asarray(img))
img_rectified.save(img_path)
print(img_name)
if __name__ == '__main__':
rectify_imgs()
标签正确性检验
完成上述所有数据集准备工作后,编写labels_shower.py模块,随机选取n张图片,使用 YOLOv5内的图像加载和标记函数,校验 labels文件夹中标记是否正确转换。

# .
# ├── datasets
# │ └── UNIMIB2016
# │ ├── UNIMIB2016-annotations
# │ ├── images
# │ ├── labels
# │ └── split
# └── yolov5
# └── labels_shower.py <--
# labels_shower.py
import os
import yaml
import numpy as np
from random import sample
from utils.general import xywhn2xyxy
from utils.plots import Annotator
from utils.general import cv2
from utils.datasets import LoadImages
from utils.plots import Colors
n = 5 # how many images you want to show
# file path set
# ../datasets/UNIMIB2016/labels/
labels_path = os.path.join(os.path.pardir, 'datasets', 'UNIMIB2016', 'labels')
# ../datasets/UNIMIB2016/images/
imgs_path = os.path.join(os.path.pardir, 'datasets', 'UNIMIB2016', 'images')
# data/UNIMIB2016.yaml
cls_path = os.path.join(os.getcwd(), 'data', 'UNIMIB2016.yaml')
# model data preparation
# you shouldn't change them
pt = True
stride = 2
imgsz = (640, 640)
datasets = os.listdir(labels_path)
line_thickness = 3 # bounding box thickness (pixels)
colors = Colors() # create instance for 'from utils.plots import colors'
with open(cls_path, errors='ignore') as f:
names = yaml.safe_load(f)['names'] # class names
def labels_shower():
sources = sample(datasets, n)
for source in sources:
# Add bbox to image
with open(os.path.join(labels_path, source)) as file:
lines = file.readlines()
dataset = LoadImages(os.path.join(imgs_path, source[:-4] + '.jpg'),
img_size=imgsz, stride=stride, auto=pt)
im0s = dataset.__iter__().__next__()[2]
im0 = im0s.copy()
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
for line in lines:
annot = line.split()
c = int(annot[0]) # integer class
label = names[c]
xywhn = np.asarray([[float(i) for i in annot[1:]]])
xyxy = xywhn2xyxy(xywhn, w=annotator.im.shape[1], h=annotator.im.shape[0])
annotator.box_label(xyxy.tolist()[0], label, color=colors(c, True))
im0 = annotator.result()
cv2.imshow(str(source[:-4] + '.jpg'), im0)
# press ESC to destroy cv2 windows
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()
if __name__ == '__main__':
labels_shower()
YOLOv5 网络结构
YOLOv5模型集成了FPN多尺度检测及Mosaic数据增强和SPP结构,整体结构可以分为四个模块,具体为:输入端(Input)、主干特征提取网络(Backbone) 、Neck与输出层(Prediction) 。
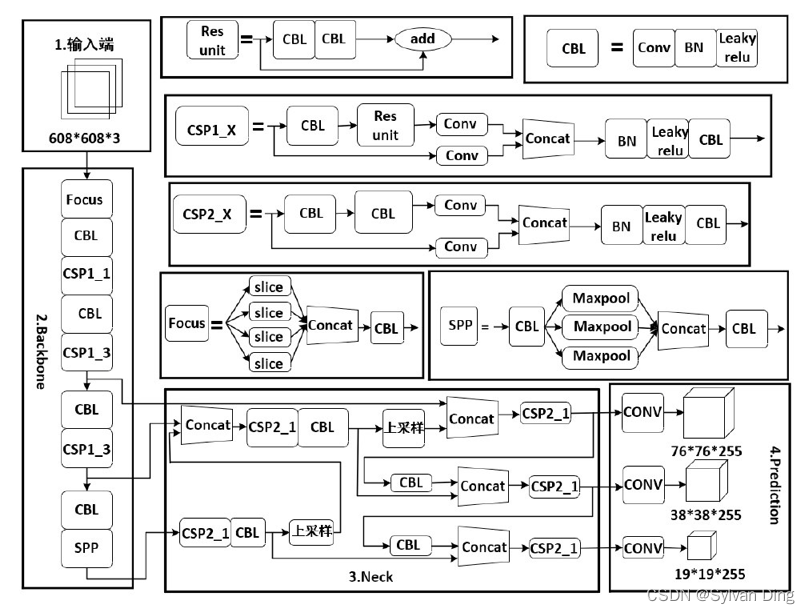
输入端
输入端(Input)主要包括了Mosaic数据增强、自适应锚框计算和自适应图片缩放三大部分。
- Mosaic数据增强是将数据集图片以随机缩放、随机裁剪、随机排布的方式进行拼接
- 自适应锚框计算是指在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框进行比对,计算两者差距,再反向迭代,更新网络参数
- 自适应图片缩放常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中
主干特征提取网络
主干特征网络提取网络Backbone由Focus结构和CSP结构组成。YOLOv5中分别设计和使用了两种不同的CSP结构,其中CSP1_X结构应用于主干特征提取网络中,同时在Neck中使用了另一种CSP2_X结构。使用CPS模块有如下优点:
- 增强网络的学习能力,使得训练出的模型,既能保持轻量化,又能有较高的准确性
- 有效降低了计算瓶颈,通过较少的计算量获得较高是检测性能
- 降低内存成本,使得训练使用一个GPU即可完成训练
Neck层
Neck层由FPN和PAN组成。FPN是通过向上采样的方法将上层的特征进行传输融合,从而得到预测特征图,其中含有两个PAN结构。通过下采样操作,将低层的特征信息和高层特征进行融合,输出预测的特征图。
FPN采用了自顶向下的结构,这样就可以进行对于强语义特征的传输;特征金字塔采用了自底向上的结构,这样就可以进行对于强定位特征的传输,这两者经过练手结合后,就可以将每一个检测层做到特征聚合,这样就成功提高了特征提取的能力。
输出端
输出端(Prediction),即网络预测层,负责在特征图上应用anchors,并生成带有类概率、目标得分和坐标的输出向量,并进行NMS非极大值抑制处理,最后输出预测结果。
Adam优化器
本文选用Adam作为模型训练过程中梯度下降的优化器,Adam优化器是AdaGrad和RMSPropAdam参数优化器的结合,它具有如下优点:
- 实现简单、计算高效、对内存需求少
- 参数的更新不受梯度伸缩变换影响
- 参数具有很好的解释性、且通常无需调整调整或者微调
- 更新步长能够被限制在大致的的范围内
- 自动调整学习率
激活函数选择
隐藏层激活函数
隐藏层使用带泄露的ReLU(Leaky ReLU)激活函数,在输入
x
<
0
xlt 0
x<0 时,保持一个很小的梯度
γ
gamma
γ,这样神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活。
采用ReLU激活函数只需要进行加、减、乘和比较的操作,计算上更加高效,ReLU函数也被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度高)。Sigmoid型激活函数会导致一个非稀疏性的神经网络,而ReLU却具有很好的稀疏性。
在优化方面,相比Sigmoid型函数的两端饱和,ReLU函数左饱和函数且
x
>
0
xgt 0
x>0 时导数为
1
1
1,在一定程度上缓解了神经网络梯度消失的问题,加速梯度下降的收敛速度。
输出层激活函数
输出层使用了Sigmoid型激活函数。使用Sigmoid型函数,其输出可以直接看成一个概率分布,使得神经网络可以更好地统计学习模型进行结合,并且它还可以看成一个软性门(Soft Gate),用来控制其他的神经元输出信息的数量。
模型优化
YOLOv5 的模型优化内容包括:
- Focus层优化:使用一个卷积层 Conv(k=6, s=2, p=2) 替换掉 backbone 中的 Focus 层;
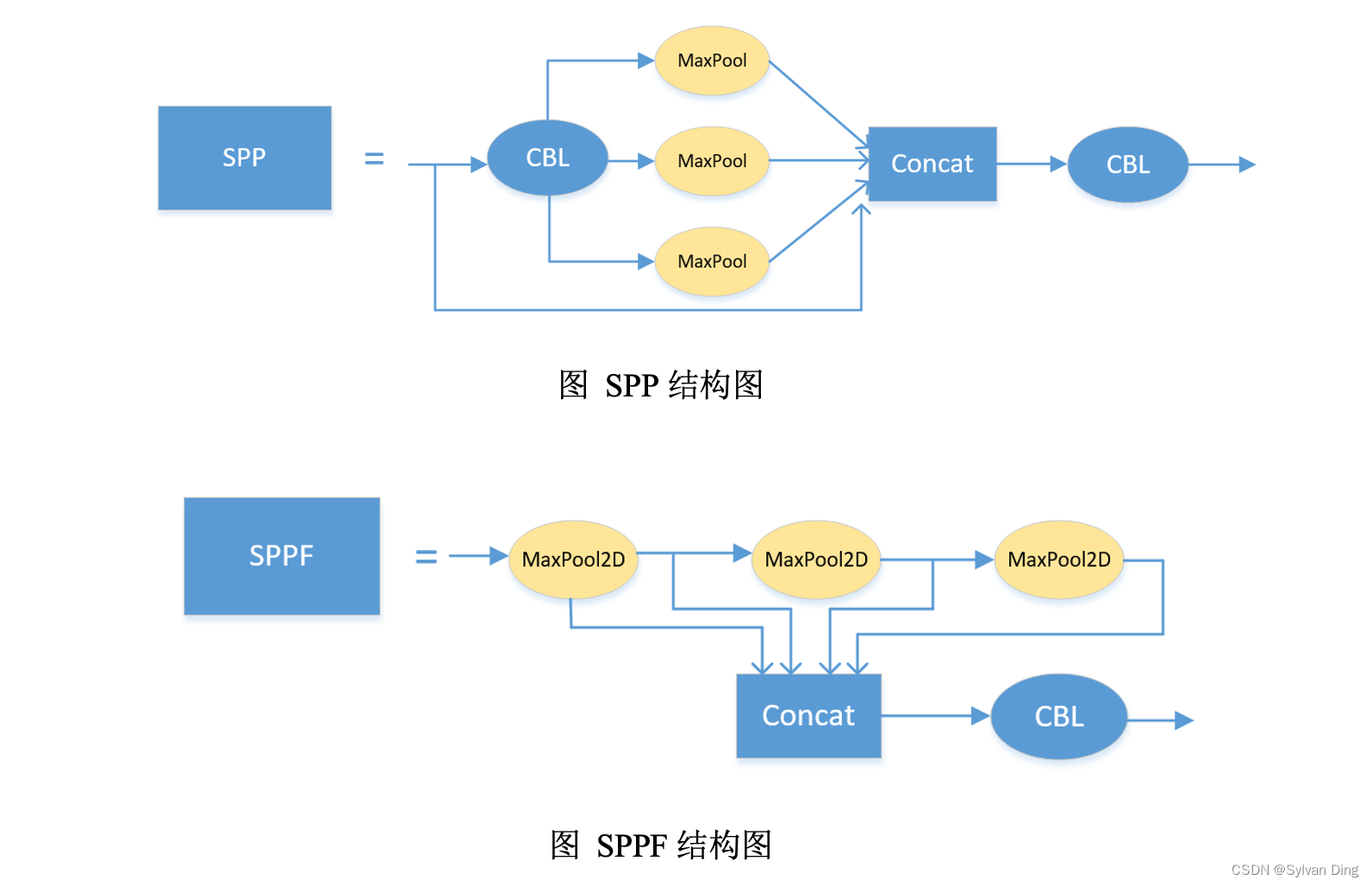
- SPP层优化:SSP空间金字塔池化层的作用是使卷积神经网络(CNN)能够输入任意大小的图片,在CNN的最后一层卷积层后面加入一层SSP层,它能使不同任意尺寸的特征图通过SSP层之后都能输出一个固定长度的向量。然后将这个固定长度的向量输入到全连接层,进行后续的分类检测任务。SPP层只通过指定三次卷积核大小,将来自CBL模块的数据进行三次池化并拼接,然后再过一个CBL,有效避免了对图像区域剪裁、缩放操作导致的图像失真等问题,解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本,增强特征图特征表达能力;
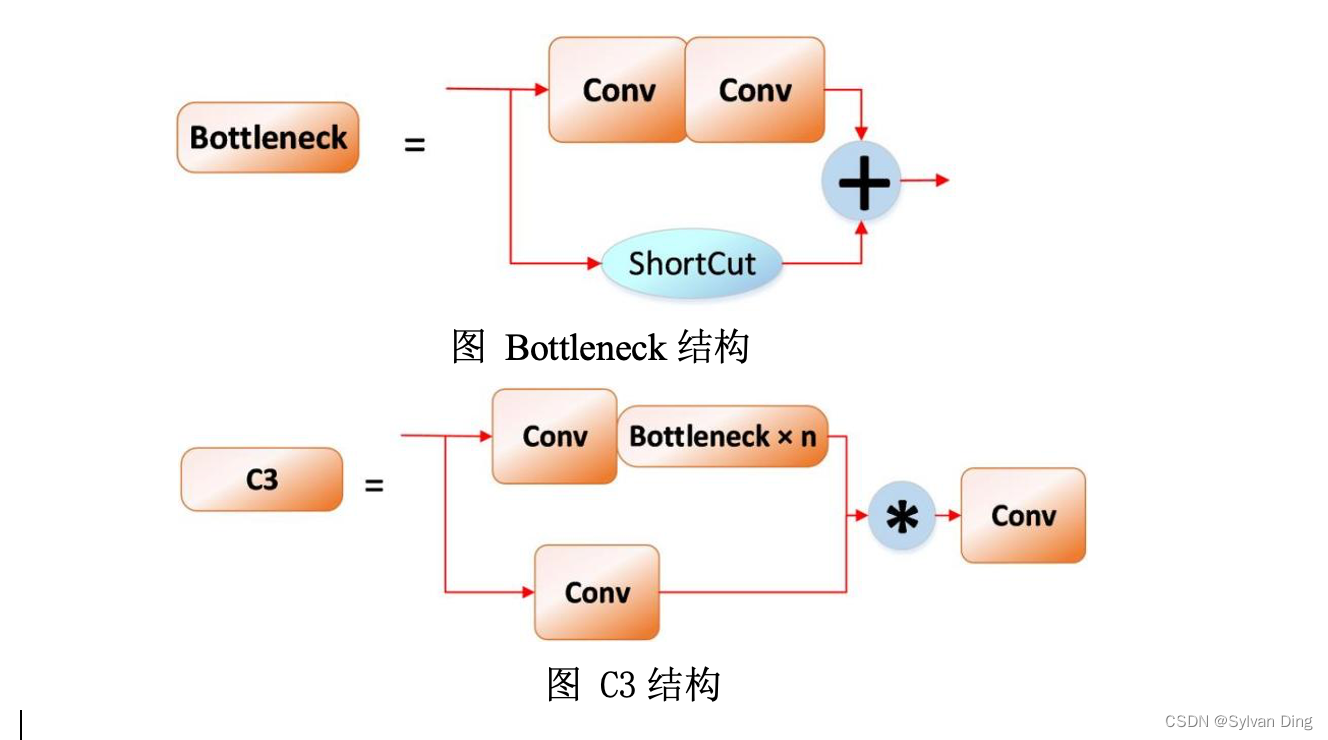
- C3层优化:Bottleneck 为基本残差块,被堆叠嵌入到C3模块中进行特征学习,它利用两个Conv模块将通道数先减小再扩大对齐,以此提取特征信息,并使用shortcut控制是否进行残差连接。在C3模块中,输入特征图会通过两个分支,第一个分支先经过一个Conv模块,之后通过堆叠的Botleneck模块对特征进行学习;另一分支作为残差连接,仅通过一个Conv模块。两分支最终按通道进行拼接后,再通过一个Conv模块进行输出。在backbone结构的最后一层的C3层改用shorcut短连接,因为原先的骨干网络最后一层是C3,而现在是SPPF层。所以最后一层改用shortcut层,这样能够使网络正常训练。
本地环境搭建
- 创建虚拟环境
- 克隆YOLOv5项目
- 安装依赖库
git clone https://github.com/ultralytics/yolov5
(venv) ➜ food_detect pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
当前项目结构
.
├── venv
├── datasets
│ └── UNIMIB2016
│ ├── images (1005)
│ └── labels (1005)
└── yolov5
注:上述目录结构中只列写了项目的关键文件和文件夹.
W&B配置
Weights & Biases可被用作替代tensorboard的监督模型训练过程的可视化工具,拥有如下几个优点:
- 其已经兼容各种深度学习框架(Pytorch/Tensorflow/Keras)
- 界面简洁无需与服务器连接,甚至可在移动端随时随地登录自己的account浏览模型训练情况
- 其不仅可以monitor深度学习loss、reward等与训练强相关的标量,还会监督CPU、GPU等硬件占用率等参数
- 不仅作为Dashboard显示一些curve,还可通过设置可视化model的weights以调整接下来的调参策略等
- 通过训练呈现的各种分析Dashboard或可视化界面可直接创建report导出pdf分享
W&B由以下四个组件构成:
- Dashboard: 实验跟踪
- Artifacts: 数据集版本控制、模型版本控制
- Sweeps: 超参数优化
- Reports: 保存和共享可重现的结果
基于上述优势,本项目选择W&B作为模型训练和结果可视化的管理平台。版本号如下,虽然YOLOv5v6.1推荐使用wandb version 0.12.10 or below.
| 版本号 |
|---|
| 0.12.11 |
# From the command line, install and log in to wandb, Copy this key and paste it into your command line when asked to authorize your account
pip install wandb==0.12.11
wandb login
环境配置说明表
| YOLOv5 | v6.1 |
|---|---|
| wandb | 0.12.11 |
| IDE | PyCharm |
| python | 3.8 |
| OS | MacOS |
模型训练准备
预训练模型的选取
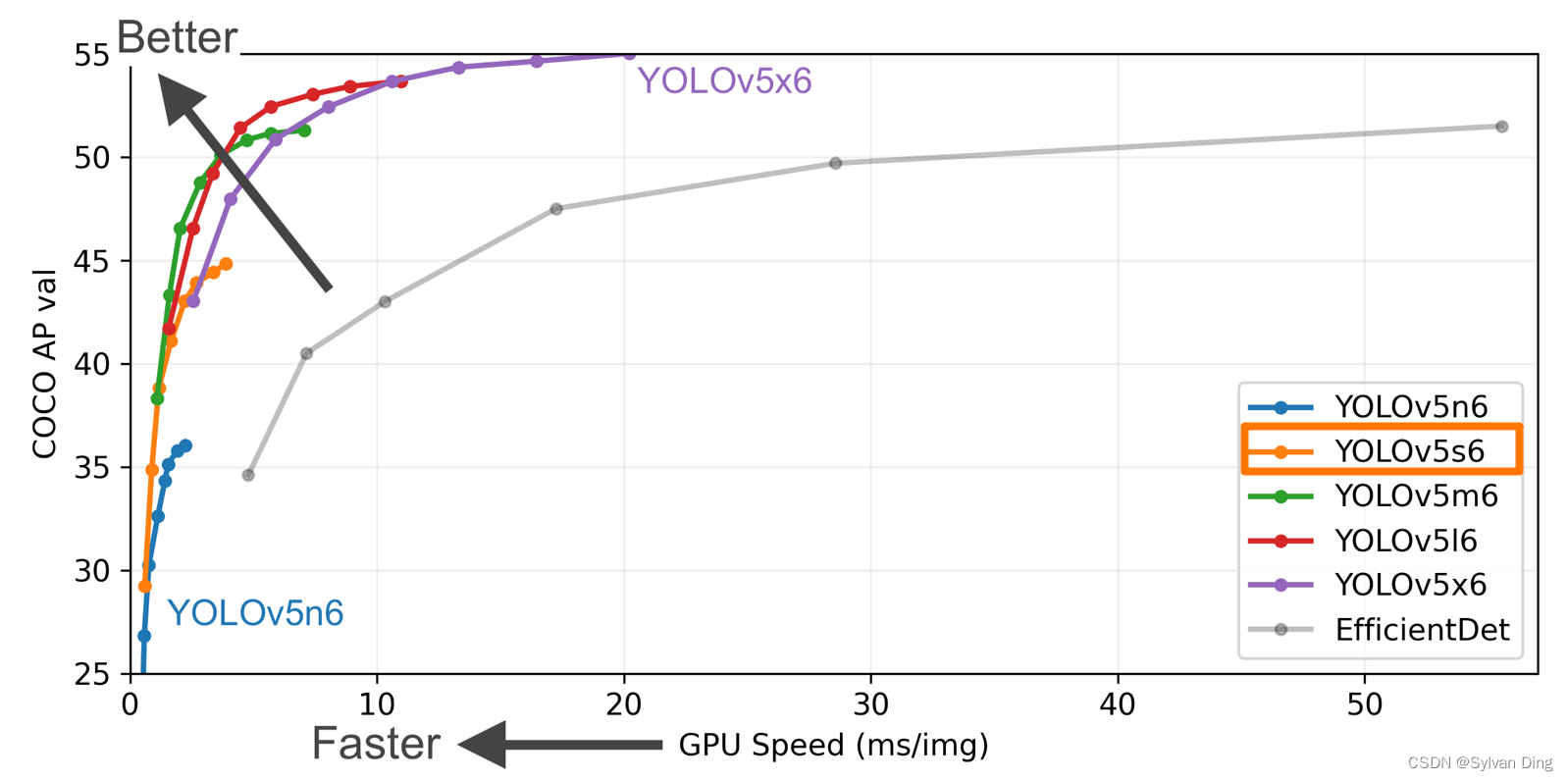
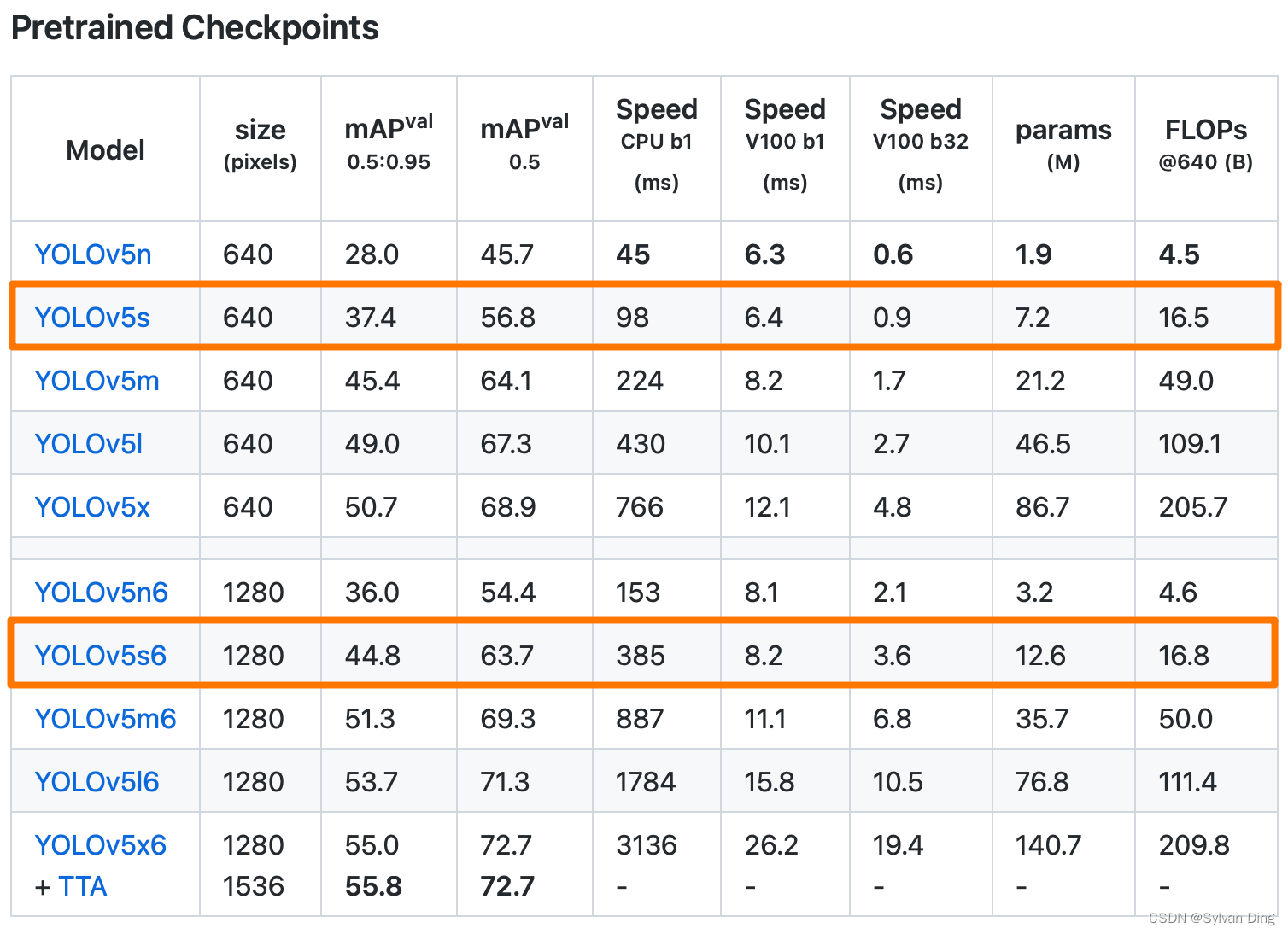
在预训练模型的选择上,为了同时兼顾菜品识别的速率和准确性,我们选择最近才发布的预训练模型YOLOv5s6. (22 Feb 2022, v6.1)
在COCO数据集上,虽然YOLOv5n在识别速度上远超其他模型,但精度相对较低。而YOLOv5s在保持着较高识别速度的前提下,识别准确性优于YOLOv5n。在近期更新的版本中,YOLOv5s6模型识别的准确性进一步提高,识别速度也有所提升,模型参数量大幅减少,故选择该预训练模型。
下载模型:YOLOv5s6.pt,放置于yolov5/文件夹下.

训练集和验证集的划分
编写脚本,将datasets/UNIMIB2016/labels中的有效数据按7:3划分训练集和验证集,验证集也做测试集之用。最终,训练集数据量为703,验证集为302. 将结果存入UNIMIB2016目录下的train.txt和test.txt.
# .
# ├── venv
# ├── datasets
# │ └── UNIMIB2016
# │ ├── splitDataset.py <--
# │ ├── images (1005)
# │ └── labels (1005)
# └── yolov5
# splitDataset.py
import os
import random
from random import shuffle
# labels relative path
# ./labels
ya_path = os.path.join(os.getcwd(), 'labels')
# images path (relative to 'dataset root dir' in UNIMIB2016.yaml)
# ./images/
img_path = os.path.join(os.getcwd(), 'images')
# output files name
output_train = 'train.txt'
output_test = 'test.txt'
# the percentage of train set
train_percent = .7
def splitDataset():
all_samples = os.listdir(ya_path)
num = len(all_samples)
train_num = int(train_percent * num)
# shuffle samples list
random.seed(82322)
shuffle(all_samples)
train_set = all_samples[:train_num]
test_set = all_samples[train_num:]
# generate train set file
with open(os.path.join(os.getcwd(), output_train), 'w') as f:
for item in train_set:
f.write(os.path.join(img_path, item[:-4] + '.jpg') + 'n')
# generate test set file
with open(os.path.join(os.getcwd(), output_test), 'w') as f:
for item in test_set:
f.write(os.path.join(img_path, item[:-4] + '.jpg') + 'n')
print('train set num = ' + str(train_num))
print('test set num = ' + str(num - train_num))
if __name__ == '__main__':
splitDataset()
模型训练文件配置
UNIMIB2016.yaml
新建yolov5/data/UNIMIB2016.yaml,内容设置如下:
# UNIMIB2016 dataset http://www.ivl.disco.unimib.it/activities/food-recognition/ (1027 available photos)
# parent
# ├── yolov5
# └── datasets
# └── UNIMIB2016 ← downloads here
path: ../datasets/UNIMIB2016 # dataset root dir
train: train.txt # train images (relative to 'path') 703 images
val: test.txt # val images (relative to 'path') 302 images
test: test.txt # test images (optional) 302 images
# Classes
nc: 73 # number of classes
names: [ 'pane', 'mandarini', 'carote', 'patate/pure', 'cotoletta', 'fagiolini', 'yogurt', 'budino', 'spinaci', 'scaloppine',
'pizza', 'pasta_sugo_vegetariano', 'mele', 'pasta_pesto_besciamella_e_cornetti', 'zucchine_umido',
'lasagna_alla_bolognese', 'arancia', 'pasta_sugo_pesce', 'patatine_fritte', 'pasta_cozze_e_vongole', 'arrosto',
'riso_bianco', 'medaglioni_di_carne', 'torta_salata_spinaci_e_ricotta', 'pasta_zafferano_e_piselli',
'patate/pure_prosciutto', 'torta_salata_rustica_(zucchine)', 'insalata_mista', 'pasta_mare_e_monti',
'polpette_di_carne', 'pasta_pancetta_e_zucchine', 'pasta_ricotta_e_salsiccia', 'orecchiette_(ragu)', 'pizzoccheri',
'finocchi_gratinati', 'pere', 'pasta_tonno', 'riso_sugo', 'pasta_tonno_e_piselli', 'piselli', 'torta_salata_3',
'torta_salata_(alla_valdostana)', 'banane', 'salmone_(da_menu_sembra_spada_in_realta)', 'pesce_2_(filetto)',
'bruscitt', 'guazzetto_di_calamari', 'pasta_e_fagioli', 'pasta_sugo', 'arrosto_di_vitello', 'stinco_di_maiale',
'minestra_lombarda', 'finocchi_in_umido', 'pasta_bianco', 'cavolfiore', 'merluzzo_alle_olive', 'zucchine_impanate',
'pesce_(filetto)', 'torta_crema_2', 'roastbeef', 'rosbeef', 'cibo_bianco_non_identificato', 'torta_crema',
'passato_alla_piemontese', 'pasta_e_ceci', 'crema_zucca_e_fagioli', 'focaccia_bianca', 'minestra',
'torta_cioccolato_e_pere', 'torta_ananas', 'rucola', 'strudel', 'insalata_2_(uova' ] # class names
my_train.py
创建 yolov5/my_train.py,编写单次训练的启动程序,并设置模型各个参数:(这一步也可融入下一目中进行——超参优化)
my_train.py使用预置超参数data/hyps/hyp.scratch-myself.yaml,优化器Adam,输入图像尺寸640,batch size = 16.
# my_train
import train
params = {'weights': 'yolov5s6.pt',
'cfg': 'hub/yolov5s6.yaml',
'data': 'UNIMIB2016.yaml',
'hyp': 'data/hyps/hyp.scratch-myself.yaml',
'epochs': 300,
'batch_size': 16,
'imgsz': 640,
'optimizer': 'Adam'}
if __name__ == '__main__':
train.run(**params)
图像增强
数据增强也叫数据扩增,意思是在不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。
在yolov5/data/hyps目录下,作者提供的初始超参数就包含了图像增强的参数,如下图所示(hyp.scratch-med.yaml):

图例为一次运行时(batch_size=16),经过mosaic、hsv、flip up-down、flip left-right后得到的增强图片。

超参数调优
YOLOv5的开发团队在 PR #3938 中添加了对于 W&B sweep 的支持。所以,对于YOLOv5s6预训练模型的超参数调优,我们使用W&B提供的sweep工具。
参数和配置
编写yolov5/utils/loggers/wandb/sweep.yaml,确定项目路径配置和超参数搜索范围、方法等:
# sweep.yaml
# Hyperparameters for training
program: utils/loggers/wandb/sweep.py
method: random
metric:
name: metrics/mAP_0.5
goal: maximize
early_terminate:
type: hyperband
min_iter: 3
eta: 3
parameters:
# hyperparameters: set either min, max range or values list
data:
value: "data/UNIMIB2016.yaml"
weights:
value: "yolov5s6.pt"
cfg:
value: "models/hub/yolov5s6.yaml"
epochs:
value: 100
imgsz:
value: 640
optimizer:
value: "Adam"
batch_size:
values: [4, 8, 16]
lr0:
distribution: uniform
min: 0.005
max: 0.015
lrf:
distribution: uniform
min: 0.005
max: 0.015
momentum:
distribution: uniform
min: 0.92
max: 0.95
weight_decay:
distribution: uniform
min: 4e-4
max: 5e-4
warmup_epochs:
value: 3.0
warmup_momentum:
value: 0.8
warmup_bias_lr:
value: 0.1
box:
distribution: uniform
min: 0.045
max: 0.055
cls:
distribution: uniform
min: 0.45
max: 0.55
cls_pw:
value: 1.0
obj:
distribution: uniform
min: 0.95
max: 1.05
obj_pw:
value: 1.0
iou_t:
distribution: uniform
min: 0.18
max: 0.22
anchor_t:
value: 4.0
fl_gamma:
value: 0.0
hsv_h:
value: 0.015
hsv_s:
value: 0.7
hsv_v:
value: 0.4
degrees:
value: 8.0
translate:
value: 0.005
scale:
value: 0.20
shear:
value: 0.0
perspective:
value: 0.0
flipud:
value: 0.7
fliplr:
value: 0.7
mosaic:
value: 0.95
mixup:
value: 0
copy_paste:
value: 0
- 超参数调优的目标是最大化
mAP@0.5 - 最优超参数搜索方法使用
random,每次迭代时随机地在超参数搜索范围中选择一组参数 - 参数范围的选取根据
data/hyps/hyp.scratch-low.yaml来确定,hyp.scratch-low.yaml也被用来作为 baseline,在开始 sweep 前先以该参数训练模型 - sweeping过程中,使用
hyperband方法对表现较差的迭代进行减枝(prune),提前结束该次超参尝试,加速模型超参数优化速度。参数设置:η=
3
eta=3
η=3,m
i
n
_
i
t
e
r
=
3
min_iter=3
min_iter=3. 意味着每轮运行将在
[3, 9, 27, 81]次brackets时,对模型优化目标进行评估,及时终止无效的运行
Randomsearch chooses a random set of values on each iteration.- Hyperparameters. Default hyperparameters are in hyp.scratch.yaml. We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP.
- Hyperband stopping evaluates whether a program should be stopped or permitted to continue at one or more pre-set iteration counts, called “brackets”. When a run reaches a bracket, its metric value is compared to all previous reported metric values and the run is terminated if its value is too high (when the goal is minimization) or low (when the goal is maximization).
调优程序运行(sweep)
运行超参数调优程序,迭代次数100次.
# get the sweep id
wandb sweep --project YOLOv5 utils/loggers/wandb/sweep.yaml
# set a target to automatically stop the sweep
NUM=100
# input the sweep id got in preceding step
SWEEPID="xxxxxxxx"
# run an agent by nohup
nohup wandb agent --count $NUM sylvanding/YOLOv5/$SWEEPID > ./sweeping.log 2>&1 &
模型训练
云服务器选取
本项目的模型训练使用MistGPU平台提供的带有GPU加速功能的主机. 服务器的配置如下:
| 操作系统 | Linux-4.18.0-15-generic-x86_64-with-glibc2.27 |
|---|---|
| 显卡 | NVIDIA GeForce GTX 1080 Ti |
| 显存 | 11 Gbps |
| CPU | Intel Xeon CPU E5-2678 v3 @ 2.50GHz |
YOLOv5开发环境配置如下:
| Python version | 3.8.13 |
|---|---|
| W&B CLI Version | 0.12.11 |
| PyTorch | 1.11.0 |
| Opencv | 4.5.5 |
| Cuda/cudnn | Cuda10.1/cudnn7.6.5 |
服务器环境配置
安装python3.8
# python3.8 安装
1. 以root用户或具有sudo访问权限的用户身份运行以下命令,以更新软件包列表并安装必备组件:
2. $ sudo apt update
$ sudo apt install software-properties-common
3. 将Deadsnakes PPA添加到系统的来源列表中:
$ sudo add-apt-repository ppa:deadsnakes/ppa
4. 启用存储库后,请使用以下命令安装Python 3.8:
$ sudo apt install python3.8
5. 通过键入以下命令验证安装是否成功:
$ python3.8 --version
上传项目
项目文件的组织结构如下(整个项目的必要文件均打包到model_training/文件夹下):
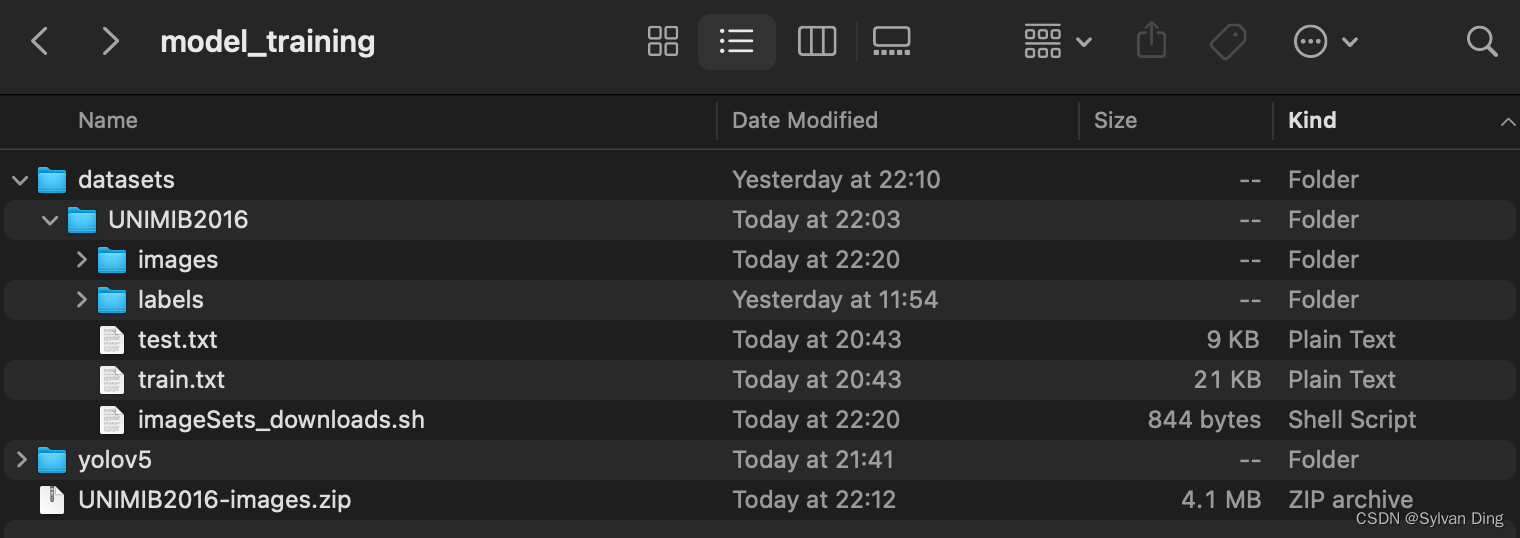
labels/文件夹存有前文得到的yolov5格式.txt标记文件1005份test.txt,train.txt存放前文划分好的测试集、训练集图片文件路径yolov5/存放上文修改的yolov5项目- 初始时,
images文件夹为空,需要编写脚本下载、解压、修正图片,图片压缩文件UNIMIB2016-images.zip - 上图
UNIMIB2016中缺少rectify_imgs.py,应当添加进来
scp -r -P61500 /Users/sylvanding/Downloads/food_detect/model_training.zip mist@ygg.mistgpu.xyz:~/
创建虚拟环境和安装项目依赖
pip install virtualenv
whereis python3.8 # get python3.8 path
virtualenv -p /usr/bin/python3.8 venv # use python3.8 as interpreter
source venv/bin/activate
cd yolov5
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
下载数据和初始化W&B
# 注意:下载速度可能很慢
bash datasets/UNIMIB2016/imageSets_downloads.sh
# 初始化W&B
wandb login
服务器图片处理脚本
编写imageSets_downloads.sh,以下载、解压、修正图片:
#!/bin/bash
# Download UNIMIB2016 dataset
# http://www.ivl.disco.unimib.it/activities/food-recognition/
# created by Sylvan Ding -- https://blog.csdn.net/IYXUAN
# 2022.04.22 -- sylvanding@qq.com, sylvanding.online
# Example usage: bash datasets/UNIMIB2016/imageSets_downloads.sh
# before execution, you need to install wget and zip!
# parent ← you should be here
# ├── yolov5
# └── datasets
# └── UNIMIB2016
# ├── labels
# └── images ← downloads here
# Download/unzip images
d='./datasets/UNIMIB2016/images' # unzip directory
file='UNIMIB2016-images.zip' # images.zip
url='wget http://www.ivl.disco.unimib.it/download/http://www.ivl.disco.unimib.it/minisites/UNIMIB2016/UNIMIB2016-images.zip'
wget $url
echo 'Unzipping...'
unzip -q -j -d $d $file
echo 'Downloaded successfully!'
python3.8 $d/../rectify_imgs.py
echo 'Rectified successfully!'
运行截图
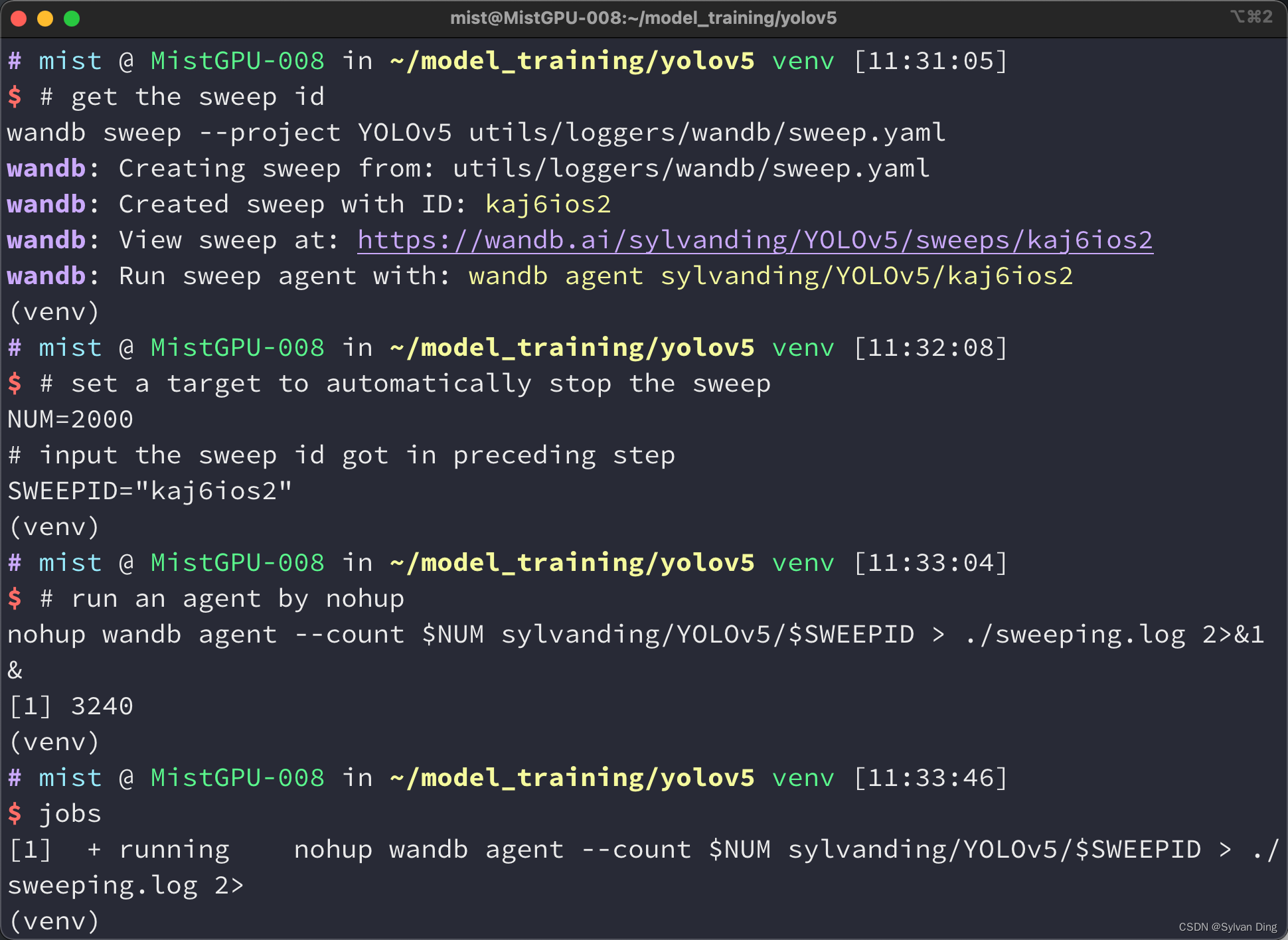
常见错误
Arial.ttf
- 第一次启动,需要下载 Arial.ttf 字体,卡住.
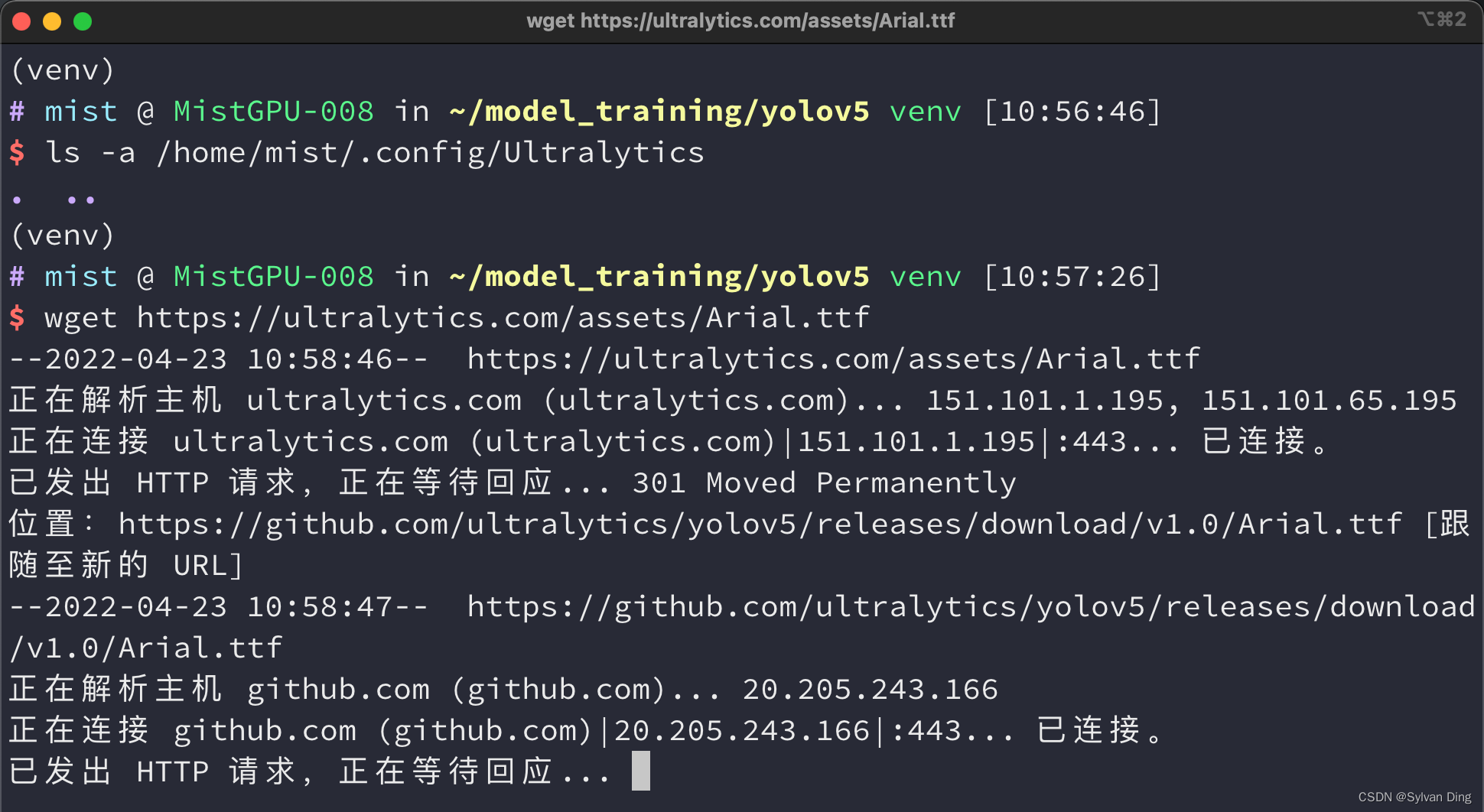
- 解决方法:
在自己主机上下载好再上传到服务器,或者用 wget 再服务器上下载再移至指定字体文件夹
wget https://ultralytics.com/assets/Arial.ttf
scp -r -P61500 /Users/sylvanding/Downloads/Arial.ttf mist@ygg.mistgpu.xyz:/home/mist/.config/Ultralytics/
图片下载速度慢
- 图片数据集下载速度慢,用腾讯云SVM下载,下载好后传至自己的主机上,再用 MistGPU 提供的云储存上传数据集即可
# 从“云端”拷贝数据集到项目文件夹
cp -v /data/UNIMIB2016-images.zip ~/model_training
Cuda out of memory
- 出现
Cuda is out of memory,内存或显存不足,应该 kill 释放其他占用内存的进程
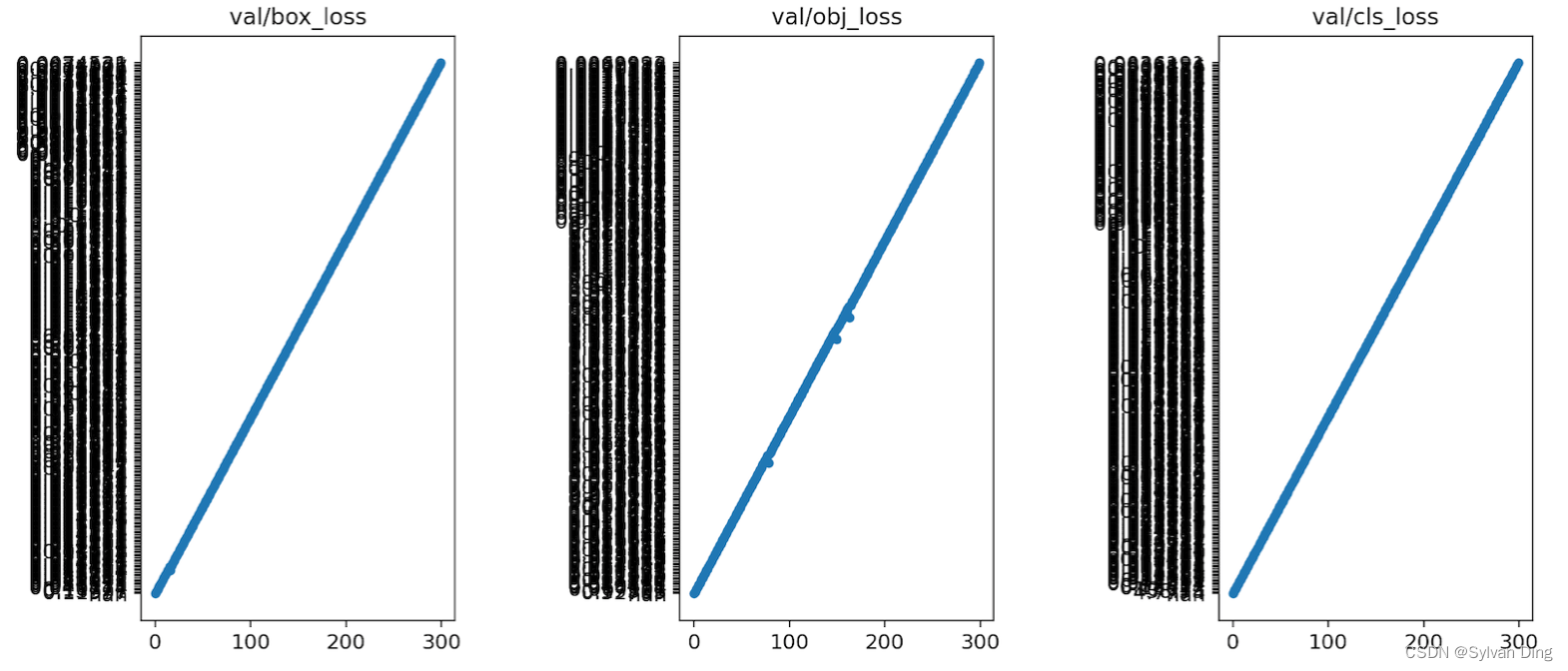
results.png 生成问题
- #7650 When generating results.png, bug happened with disorder on Y-axis of val/box_loss, val/obj_loss and val/cls_loss
结果分析
Metrics
precision & recall
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
=
T
P
a
l
l
d
e
t
e
c
t
i
o
n
s
precision = frac{TP}{TP+FP} = frac{TP}{mathrm{all detections}}
precision=TP+FPTP=all detectionsTP
r
e
c
a
l
l
=
T
P
T
P
+
F
N
=
T
P
a
l
l
g
r
o
u
n
d
t
r
u
t
h
s
recall = frac{TP}{TP+FN} = frac{TP}{mathrm{all ground truths}}
recall=TP+FNTP=all ground truthsTP
- Precision 指的是预测出的样本中正例比例(查准率)
- Recall 指的是所有正例中预测出的正例比例(查全率)
all detections是所有bounding box的数量all ground truths是所有ground truths的数量
在目标检测(object detection)中,混淆矩阵的定义如下:
| C o n f i d e n c e ≥ T h r e s h o l d 2 Confidencege Threshold_2 Confidence≥Threshold2 | C o n f i d e n c e < T h r e s h o l d 2 Confidencelt Threshold_2 Confidence<Threshold2 | |
|---|---|---|
| I o U ≥ T h r e s h o l d 1 IoUge Threshold_1 IoU≥Threshold1 | TP | FN |
| I o U < T h r e s h o l d 1 IoUlt Threshold_1 IoU<Threshold1 | FP | TN |
- I
o
U
=
a
r
e
a
o
f
o
v
e
r
l
a
p
a
r
e
a
o
f
u
n
i
o
n
=
a
r
e
a
(
B
p
∩
B
g
t
)
a
r
e
a
(
B
p
∪
B
g
t
)
IoU = frac{mathrm{area of overlap}}{mathrm{area of union}} = frac{area(B_pcap B_{gt})}{area(B_pcup B_{gt})}
IoU=area of unionarea of overlap=area(Bp∪Bgt)area(Bp∩Bgt)
- T
h
r
e
s
h
o
l
d
1
Threshold_1
Threshold1 为I
o
U
IoU
IoU 阈值
- T
h
r
e
s
h
o
l
d
2
Threshold_2
Threshold2 为C
o
n
f
i
d
e
n
c
e
Confidence
Confidence 分类置信度阈值
mAP
在不同语境下,mAP主要针对COCO数据集,AP主要针对VOC数据集。mAP(mean Average Precision)是 AP 的平均值,即计算在各个分类类别上的 AP 后求平均所得。AP 的求法如下:
- 根据 BB(bounding box)的C
o
n
f
i
d
e
n
c
e
Confidence
Confidence 由高到低排序
- 依次以各个 BB 的C
o
n
f
i
d
e
n
c
e
Confidence
Confidence 为T
h
r
e
s
h
o
l
d
2
Threshold_2
Threshold2 (包括 0、1)
- 依次计算在此分类置信度下,该分类的r
e
c
a
l
l
recall
recall 和p
r
e
c
i
s
i
o
n
precision
precision,绘制 P-R 曲线
- 根据不同的策略,计算 AUC(area under the curve),即 AP
在VOC物体检测任务中,Pascal VOC 2008 中设置
T
h
r
e
s
h
o
l
d
1
=
0.5
Threshold_1=0.5
Threshold1=0.5,使用差值平均精确度(interpolated average precision)的评测方法。绘制 P-R 曲线后,选取横轴上的11个点(间隔为0.1)所对应的最大精度,然后再取平均作为最终检测的平均精确度,其表达式如下:
A
P
=
1
11
∑
r
∈
{
0
,
0.1
,
…
,
1
}
P
i
n
t
e
r
p
(
r
)
AP=frac{1}{11} sum _{rin {0,0.1,dots , 1 }} P_{interp} (r)
AP=111r∈{0,0.1,…,1}∑Pinterp(r)
P
i
n
t
e
r
p
(
r
)
=
max
r
′
≥
r
P
(
r
′
)
P_{interp} (r) = mathop {max } limits _{r’ge r} P(r’)
Pinterp(r)=r′≥rmaxP(r′)
其中,
r
r
r 是横轴召回率的值,
P
i
n
t
e
r
p
(
r
)
P_{interp}(r)
Pinterp(r) 是
r
r
r 时的差值精度,
P
(
r
)
P(r)
P(r) 是 r 对应的纵轴精度。
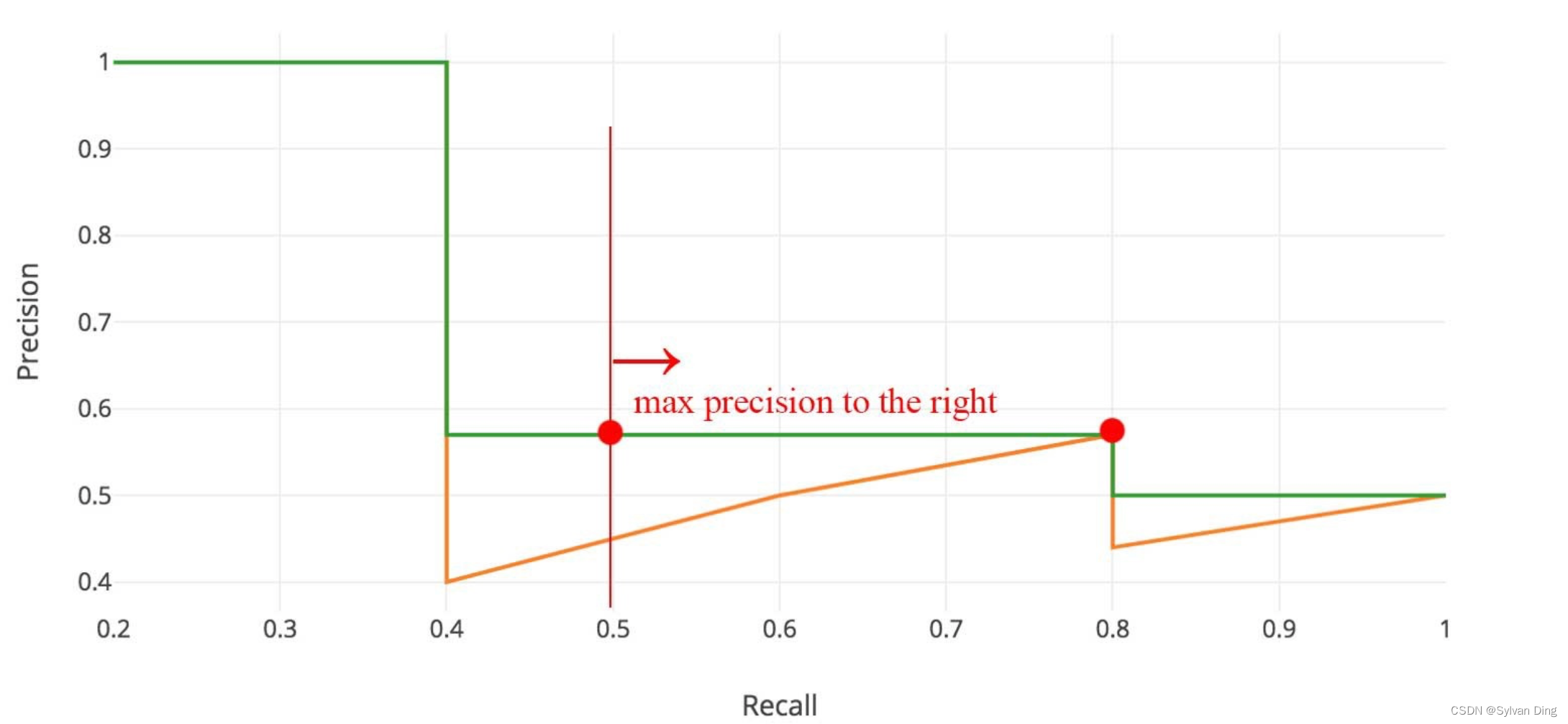
在 Pascal VOC 中,检测结果只评测了
T
h
r
e
s
h
o
l
d
1
=
0.5
Threshold_1=0.5
Threshold1=0.5 阈值下的 mAP 值(记为
m
A
P
@
0.5
mAP@0.5
mAP@0.5 )。相比 VOC 而言,COCO 数据集的评测则更加全面。
COCO 评估了在不同的交并比
[
0.5
:
0.05
:
0.95
]
[0.5:0.05:0.95]
[0.5:0.05:0.95] 下的 mAP,并且在最后以这些阈值下的 mAP 的平均作为结果,记为
m
A
P
@
[
0.5
:
0.95
]
mAP@[0.5:0.95]
mAP@[0.5:0.95]. 不仅评估到物体检测模型的分类能力,同时也能体现出检测模型的定位能力。
预测的时候会产生很多FP,为了减少FP的数量,一般检测器的最后都会引入一步Non-maximum Suppression(NMS),以去除一部分重复预测的bounding box,YOLOv5中采用加权NMS的方式。
Loss Function
YOLOv1 的损失函数包括三部分,分别是定位损失、置信度损失和分类损失,其形式如下:
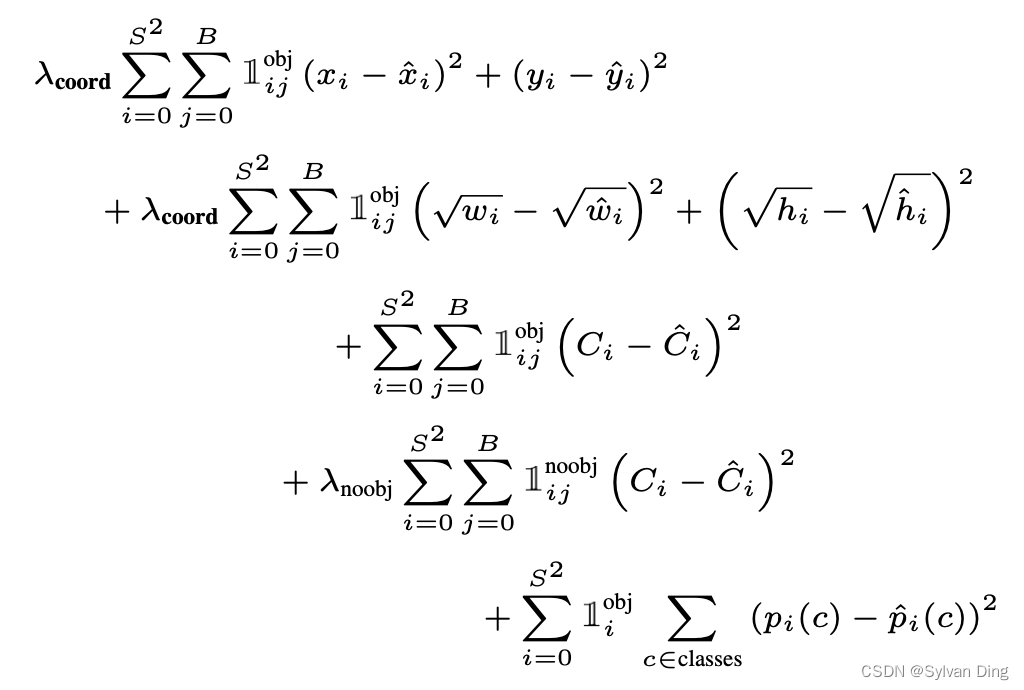
YOLOv5 改进了损失函数,进一步提高了模型的收敛速度和训练稳定性,避免了梯度消失和梯度爆炸。YOLOv5 的损失函数也有三部分构成:
- Localization loss 定位损失(又称
box loss,是预测框与 GT 之间的误差) - Confidence loss 置信度损失(又称
obj loss, Objectness of the box) - Classification loss 分类损失(
cls loss)
总损失函数是上述三者的加权和,通常置信度损失取最大权重、矩形框损失(或定位损失)和分类损失的权重次之。
YOLOv5 使用 CIoU loss 计算定位损失,置信度和分类损失都用 BCE loss 计算。
定位损失
对于矩形框的预测损失来说,可用 L1、L2 或 smooth L1 损失函数来描述。训练后期,L1 损失函数会导致其值在某范围内波动,难以收敛。虽然 L2 损失函数在 0 点处可导,最终可以收敛,但在训练前期,可能会导致梯度爆炸问题,从而训练没能朝着最优化的方向进行。smooth L1 损失函数将二者优点相结合,即避免了梯度爆炸,又避免了不熟练问题。上述计算矩形框的 L1、L2、smooth L1 损失时有一个共同点,都是分别计算矩形框中心点 x 坐标、中心点 y 坐标、宽、高的损失,最后再将四个损失值相加得到该矩形框的最终损失值。这种计算方法的前提假设是中心点 x 坐标、中心点 y 坐标、宽、高这四个值是相互独立的,实际上它们具有相关性,所以该计算方法存在问题。
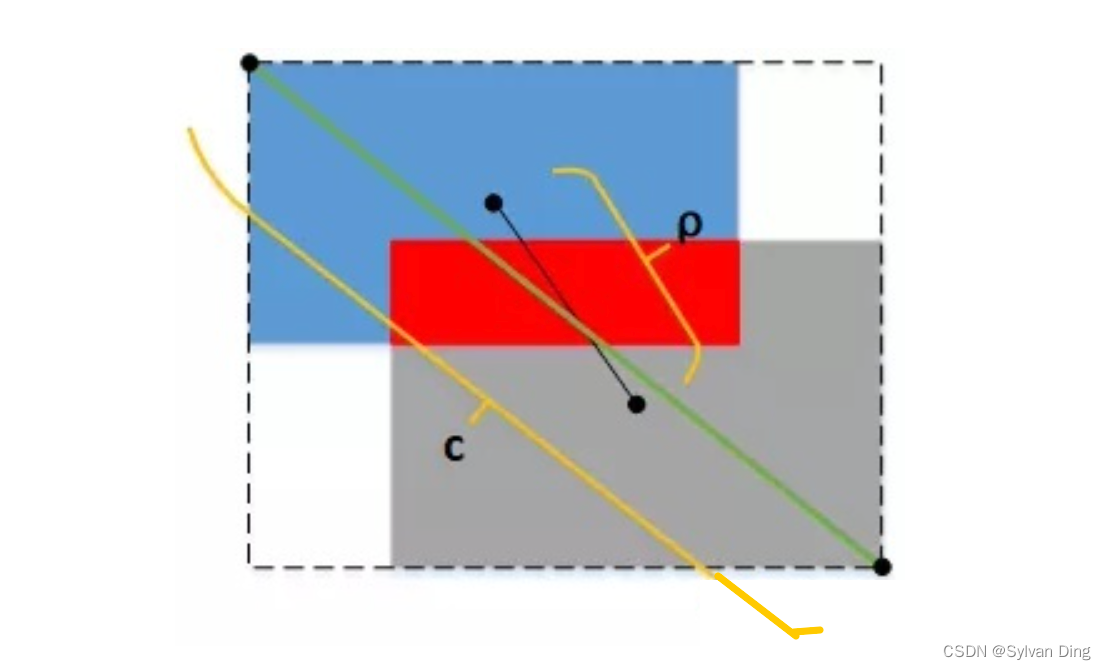
于是,IoU系列损失函数(IoU、GIoU、DIoU、CIoU)又被陆续提了出来。IoU loss 关注预测框和 GT 的交并比;GIoU loss 把包围预测框和 GT 的最小矩形框的面积也加入到计算中,解决了 IoU loss 中,当两个矩形框完全没有重叠区域时,无论它们距离多远,它们的 IoU 都为 0,导致梯度也为 0,因而无法优化的情况;DIoU loss,把两矩形框的中心点距离
ρ
rho
ρ、外接矩形框的对角线长度
c
c
c 都考虑进去,使训练更稳定、收敛更快。YOLOv5使用 CIoU loss 来衡量矩形框的损失。
CIoU loss 将重叠面积、中心点距离、宽高比同时加入了计算,其计算公式如下:
C
I
o
U
=
I
o
U
−
ρ
2
c
2
−
α
v
=
D
I
o
U
−
α
v
CIoU = IoU – frac{rho ^2}{c^2} – alpha v= DIoU – alpha v
CIoU=IoU−c2ρ2−αv=DIoU−αv
v
=
4
π
2
(
arctan
w
g
t
h
g
t
−
arctan
w
p
r
e
d
h
p
r
e
d
)
2
v = frac{4}{pi ^2} left ( arctan frac{w_{gt}}{h_{gt}} – arctan frac{w_{pred}}{h_{pred}} right ) ^2
v=π24(arctanhgtwgt−arctanhpredwpred)2
α
=
v
1
−
I
o
U
+
v
alpha = frac{v}{1-IoU+v}
α=1−IoU+vv
l
o
s
s
C
I
o
U
=
1
−
C
I
o
U
loss_{CIoU} = 1-CIoU
lossCIoU=1−CIoU
其中,
w
g
t
w_{gt}
wgt、
h
g
t
h_{gt}
hgt 为 GT 宽、高,
w
p
r
e
d
w_{pred}
wpred、
h
p
r
e
d
h_{pred}
hpred 为预测框宽、高,
ρ
rho
ρ 是两框中心点距离,
c
c
c 是是包围两框的最小矩形框对角线长度,
v
v
v 是两框宽高比的相似度,
α
alpha
α 是
v
v
v 的影响因子。
IoU 越大,两框的重叠区域越大,则
α
α
α 越大,从而
v
v
v 的影响越大,对宽高比的惩罚力度越大,着重优化宽高比;反之,IoU 越小,两框的重叠区域越小,
α
α
α 越小,从而
v
v
v 的影响越小,对两框距离的惩罚力度越大,着重优化距离。
置信度损失
YOLOv5 将一张输入的
640
×
640
640times 640
640×640 图像分割成的
N
×
N
Ntimes N
N×N 网格,每个网格预测
M
M
M 个预测框(anchor),所以总共预测了
M
×
N
×
N
Mtimes Ntimes N
M×N×N 个预测框。每个预测框的预测信息包括矩形框信息、置信度、分类概率。
- 矩形框:表征目标的大小以及精确位置
- 置信度:表征预测框的可信程度,取值范围0~1,值越大说明该矩形框中越可能存在目标
- 分类概率:表征目标的类别
由于并不是每个预测框内都存在目标,所以在训练时首先需要根据标签作初步判断,判断每个预测框内是否存在目标,以此建立 mask 矩阵(矩阵的每个元素是布尔型)。实际上,并非所有预测框都需要计算所有类别的损失函数值,而是根据 mask 矩阵来决定,决定原则如下:
- 仅 mask 矩阵对应位置为 True 的预测框需要计算 box loss 和 cls loss
- 所有预测框都要计算 obj loss,但是 mask 为 true 的预测框与 mask为 false 的预测框的置信度标签值不一样
mask 矩阵的布尔值,由 anchor 框的保留或剔除决定,依照 anchor 框和 GT 的宽高比(aspect ratio)决定 anchor 是否保留。
置信度标签的维度应该与神经网络的输出维度保持一致,因此置信度的标签也是维度为
M
×
N
×
N
Mtimes Ntimes N
M×N×N 的矩阵。计算对应预测框与目标框的 CIoU,使用 CIoU 作为该预测框的置信度标签,对 mask 矩阵为 false 的位置,预测框的置信度标签赋值 0. 当 CIoU 小于 0 时,直接取 0 值作为标签,对 CIoU 做截断。由此得到预测置信度矩阵 P.
假设置信度标签为矩阵 L,那么置信度损失的 BCE loss(二元交叉熵损失)函数定义如下:
l
o
s
s
B
C
E
(
z
,
x
,
y
)
=
−
L
(
z
,
x
,
y
)
∗
log
P
(
z
,
x
,
y
)
−
(
1
−
L
(
z
,
x
,
y
)
)
∗
log
(
1
−
P
(
z
,
x
,
y
)
)
loss_{BCE}(z,x,y)=-L(z,x,y)* log P(z,x,y) – (1-L(z,x,y))*log (1-P(z,x,y))
lossBCE(z,x,y)=−L(z,x,y)∗logP(z,x,y)−(1−L(z,x,y))∗log(1−P(z,x,y))
其中,
0
≤
z
<
M
0 le z lt M
0≤z<M,
0
≤
x
,
y
<
N
0 le x,y lt N
0≤x,y<N.
从而得到该网络的置信度损失值:
{
l
o
b
j
=
1
n
u
m
o
f
(
m
a
s
k
=
t
r
u
e
)
∑
m
a
s
k
=
t
r
u
e
l
o
s
s
B
C
E
(
z
,
x
,
y
)
l
n
o
b
j
=
1
n
u
m
o
f
(
m
a
s
k
=
f
a
l
s
e
)
∑
m
a
s
k
=
f
a
l
s
e
l
o
s
s
B
C
E
(
z
,
x
,
y
)
l
o
s
s
o
b
j
=
a
∗
l
o
b
j
+
(
1
−
a
)
∗
l
n
o
b
j
left{begin{matrix} l_{obj} &=& frac{1}{num of (mask=true)} sum _{mask=true} loss_{BCE}(z,x,y) \ l_{nobj} &=& frac{1}{num of (mask=false)} sum _{mask=false} loss_{BCE}(z,x,y) \ loss_{obj} &=& a*l_{obj}+(1-a)*l_{nobj} end{matrix}right.
⎩⎨⎧lobjlnobjlossobj===num of (mask=true)1∑mask=truelossBCE(z,x,y)num of (mask=false)1∑mask=falselossBCE(z,x,y)a∗lobj+(1−a)∗lnobj
其中,
a
a
a 为 mask = true 时的置信度损失权重,
a
a
a 越大,网络训练时越专注于 mask = true 的正样本情况。为了使训练更专注于正样本,后来 Focal loss 又被提了出来。
分类损失
为了减少过拟合、增加训练的稳定性,YOLOv5 对独热码标签做了平滑操作,如下所示:
l
a
b
e
l
s
m
o
o
t
h
=
l
a
b
e
l
∗
(
1
−
α
)
+
α
/
c
l
a
s
s
n
u
m
label_{smooth} = label*(1-alpha )+alpha /class num
labelsmooth=label∗(1−α)+α/classnum
α
alpha
α 是平滑系数,
l
a
b
e
l
label
label 是经过独热编码后的标签向量。
接着,使用 BCE loss 函数计算矩阵中每个 mask=true 元素的分类损失并累加求平均,得到总的分类损失,计算过程如下:
{
l
o
s
s
B
C
E
(
z
,
x
,
y
,
c
)
=
−
L
s
m
o
o
t
h
(
z
,
x
,
y
,
c
)
∗
log
P
(
z
,
x
,
y
,
c
)
−
(
1
−
L
s
m
o
o
t
h
(
z
,
x
,
y
,
c
)
)
∗
log
(
1
−
P
(
z
,
x
,
y
,
c
)
)
l
o
s
s
c
l
s
=
1
c
l
a
s
s
n
u
m
∗
n
u
m
o
f
(
m
a
s
k
=
t
r
u
e
)
∑
m
a
s
k
=
t
r
u
e
l
o
s
s
B
C
E
(
z
,
x
,
y
,
c
)
left{begin{matrix} loss_{BCE}(z,x,y,c) &=& -L_{smooth}(z,x,y,c)* log P(z,x,y,c) – (1-L_{smooth}(z,x,y,c))*log (1-P(z,x,y,c)) \ loss_{cls} &=& frac{1}{classnum * num of (mask=true)} sum _{mask=true} loss_{BCE}(z,x,y,c) \ end{matrix}right.
{lossBCE(z,x,y,c)losscls==−Lsmooth(z,x,y,c)∗logP(z,x,y,c)−(1−Lsmooth(z,x,y,c))∗log(1−P(z,x,y,c))classnum ∗ num of (mask=true)1∑mask=truelossBCE(z,x,y,c)
其中,
L
s
m
o
o
t
h
L_{smooth}
Lsmooth 是平滑后的 GT 标签,
0
≤
c
<
c
l
a
s
s
n
u
m
0le clt classnum
0≤c<classnum 对应样本类别数.
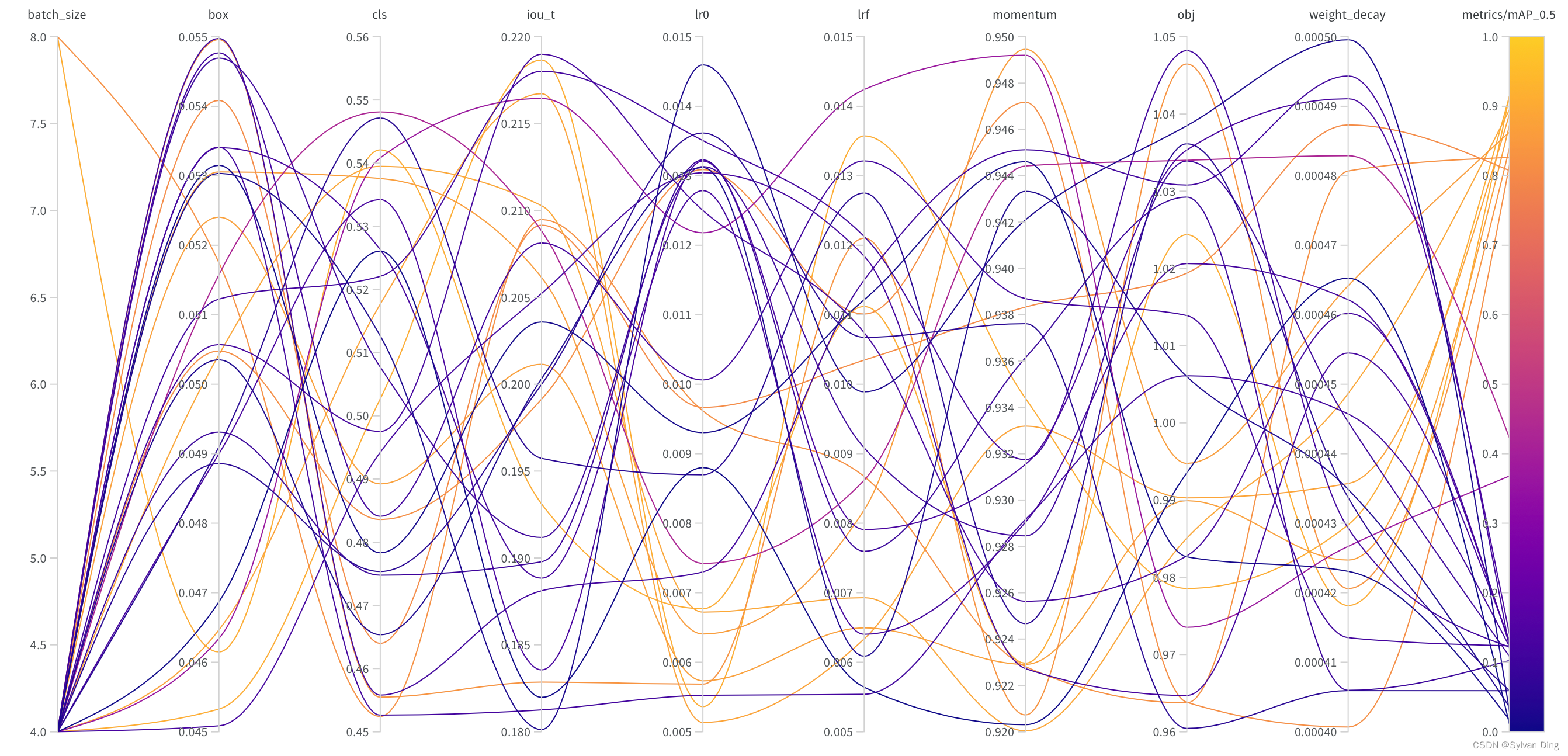
sweep超参数调优结果
相比于AutoML框架的超参数调优,wandb sweeps具有更强的实验管理和数据可视化的能力。wandb sweeps具有一下几个优点:
- 较好的可视化效果
- 较小的代码入侵
- 较好的实验管理
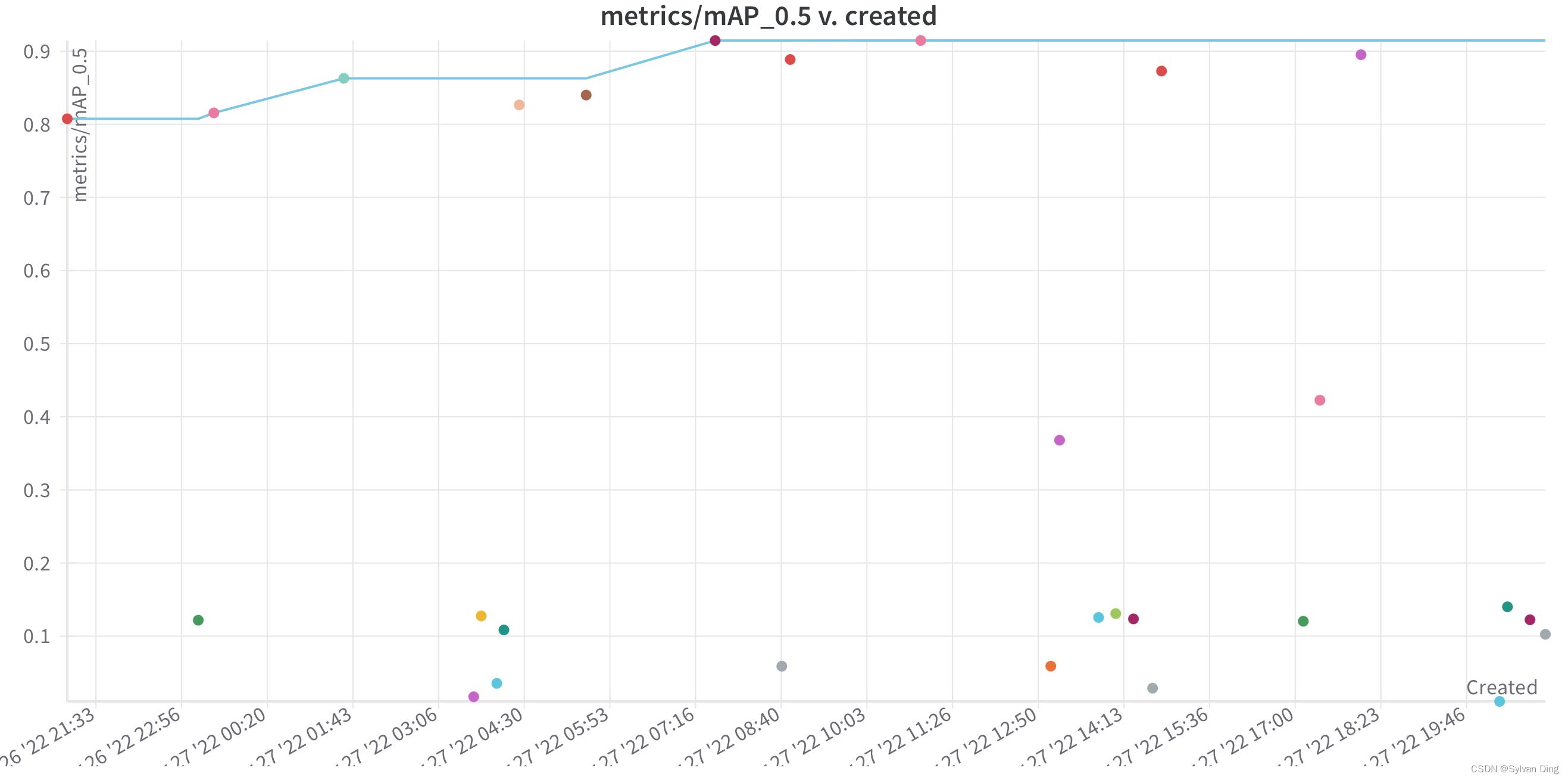
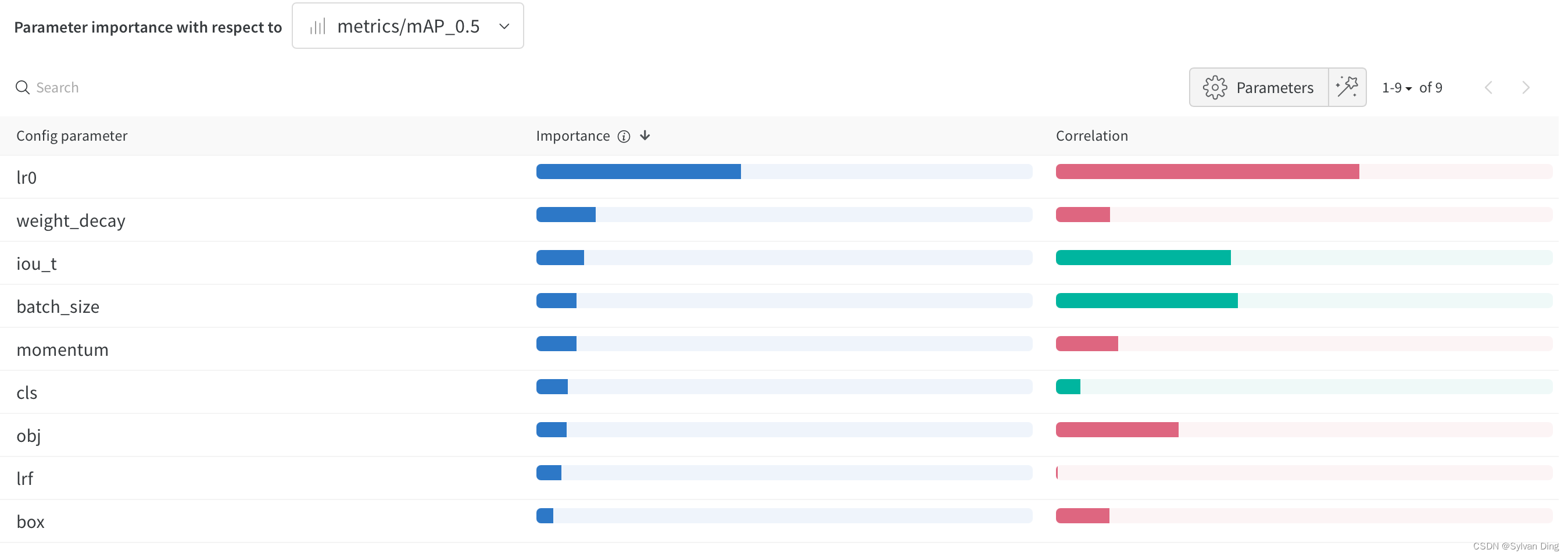
经过sweep后得到的平行坐标图(parallel coordinates plot)、散点图和相关性分析图如下所示。其中,学习率 lr0 对 mAP@0.5的影响最大,呈负相关趋势。
选取较优参数进行训练
根据 sweep 的结果,选取 mAP@0.5 值最高的超参数训练模型,具体参数如下所示(未列出参数和data/hyps/hyp.scratch-low.yaml一致,对结果的影响不大):
| weights | yolov5s6.pt |
|---|---|
| cfg | hub/yolov5s6.yaml |
| epochs | 300 |
| batch_size | 16 |
| imgsz | 640 |
| optimizer | Adam |
| lr0 | 0.01 |
| lrf | 0.01 |
| momentum | 0.937 |
| anchors | 3 |
| hsv_h/s/v | 0.015/0.7/0.4 |
| degrees | 5.0 |
| flipud/lr | 0.5/0.5 |
| mosaic | 1.0 |
结果展示
评价指标
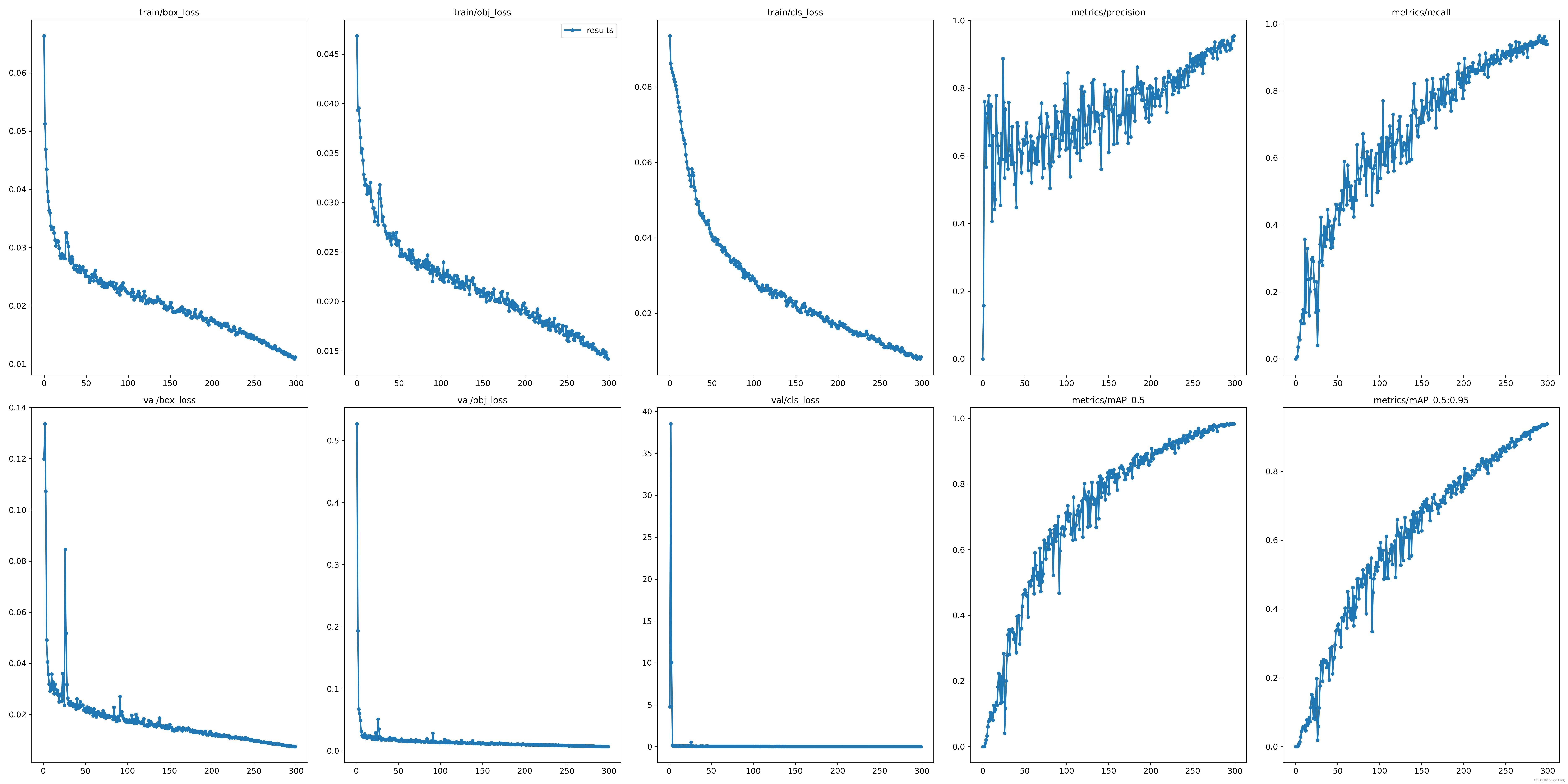
训练结束,训练集的三类损失函数均收敛。在验证集上,模型各个评价指标均高于 0.93. 最佳模型在第 299 次epoch时得到,最佳模型的评价指标如下:
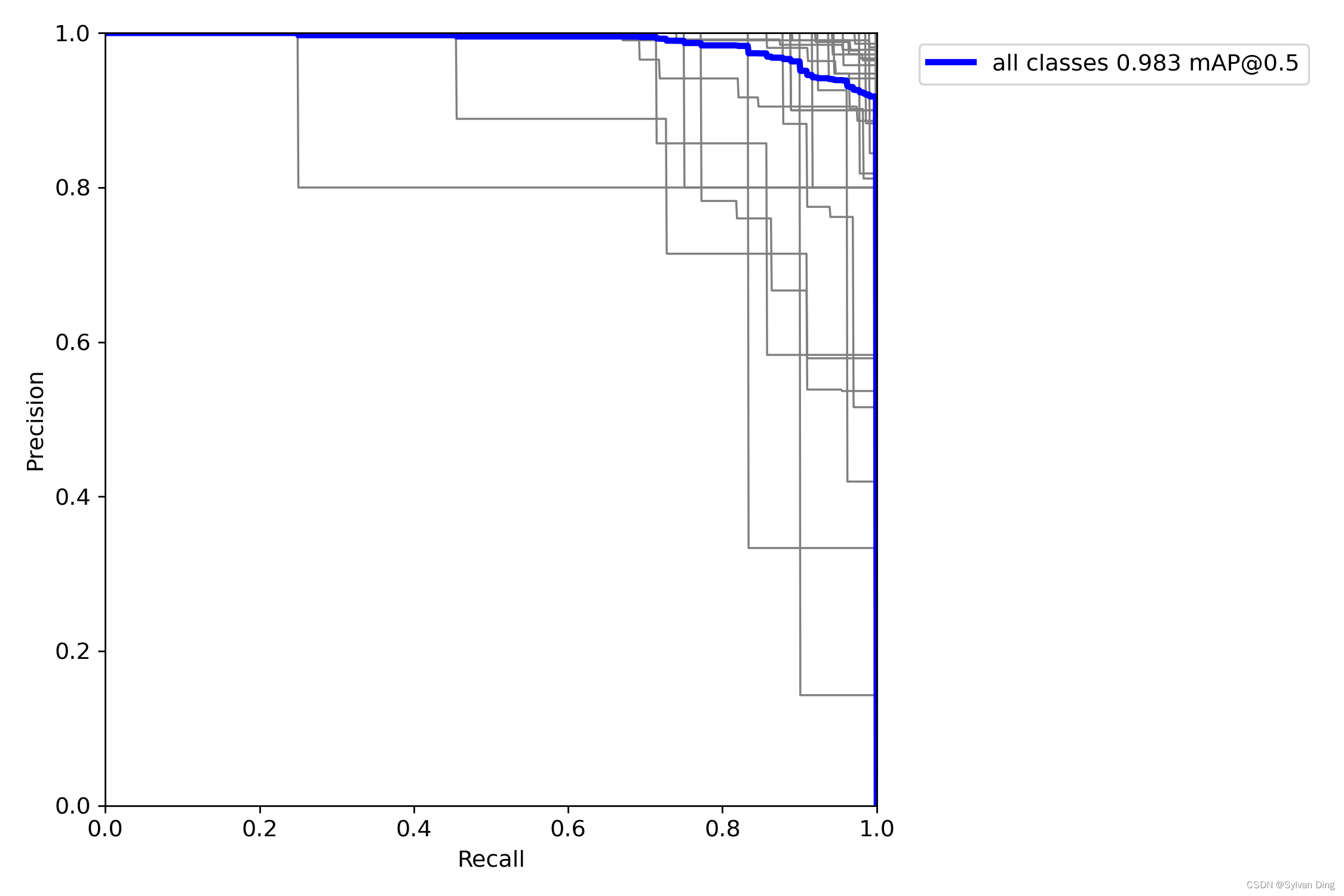
| mAP@0.5 | 0.983 |
|---|---|
| mAP@0.5:0.95 | 0.939 |
| precision | 0.954 |
| recall | 0.939 |
混淆矩阵
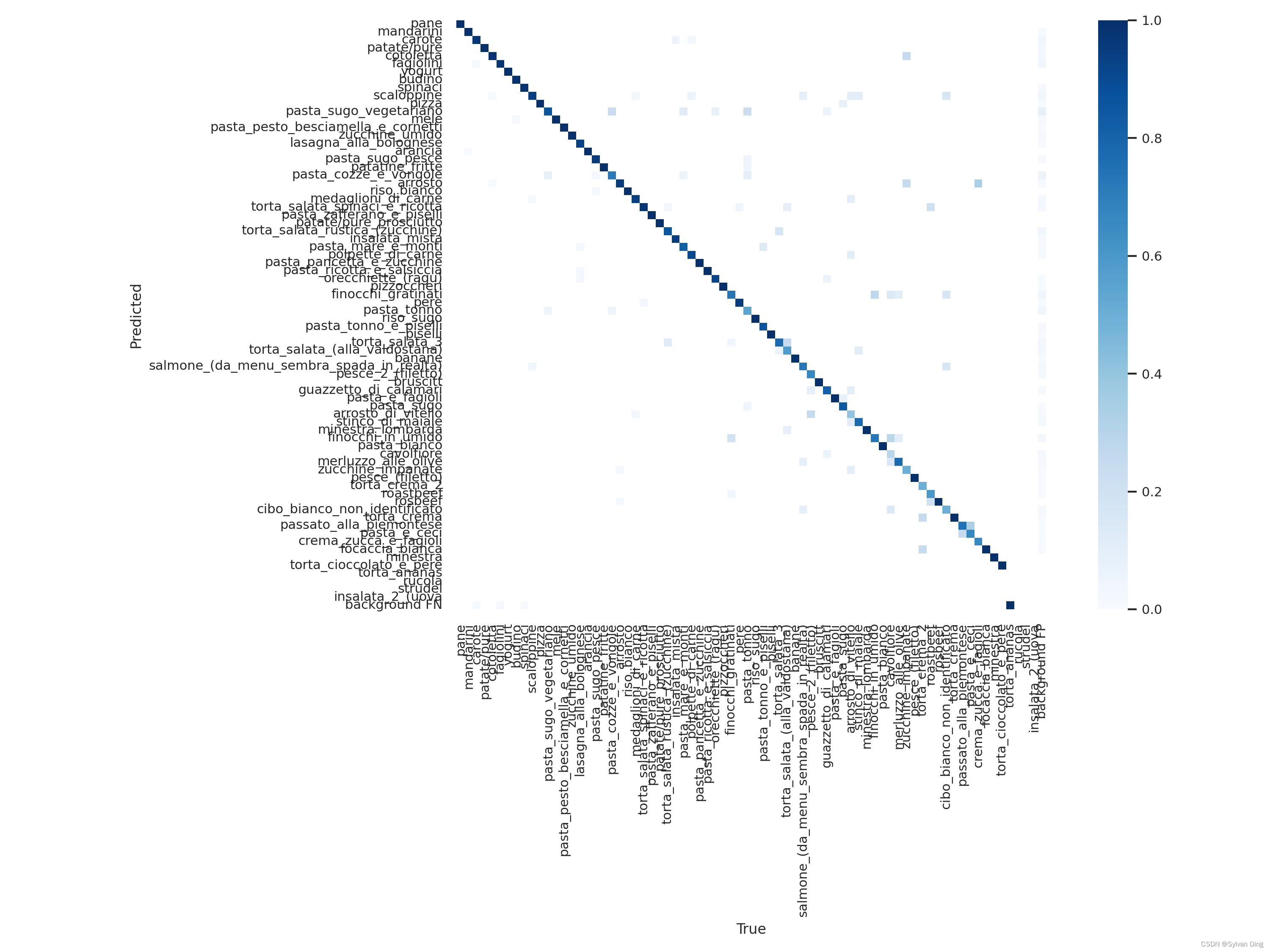
最终,模型在验证集上的混淆矩阵如下图所示,该混淆矩阵在列上做归一化,那么,对角元素表示每类的召回率,因为一小部分类别样本量太少,所以召回率较低。背景被判定为菜品的现象存在,但误判率极低。
PR曲线
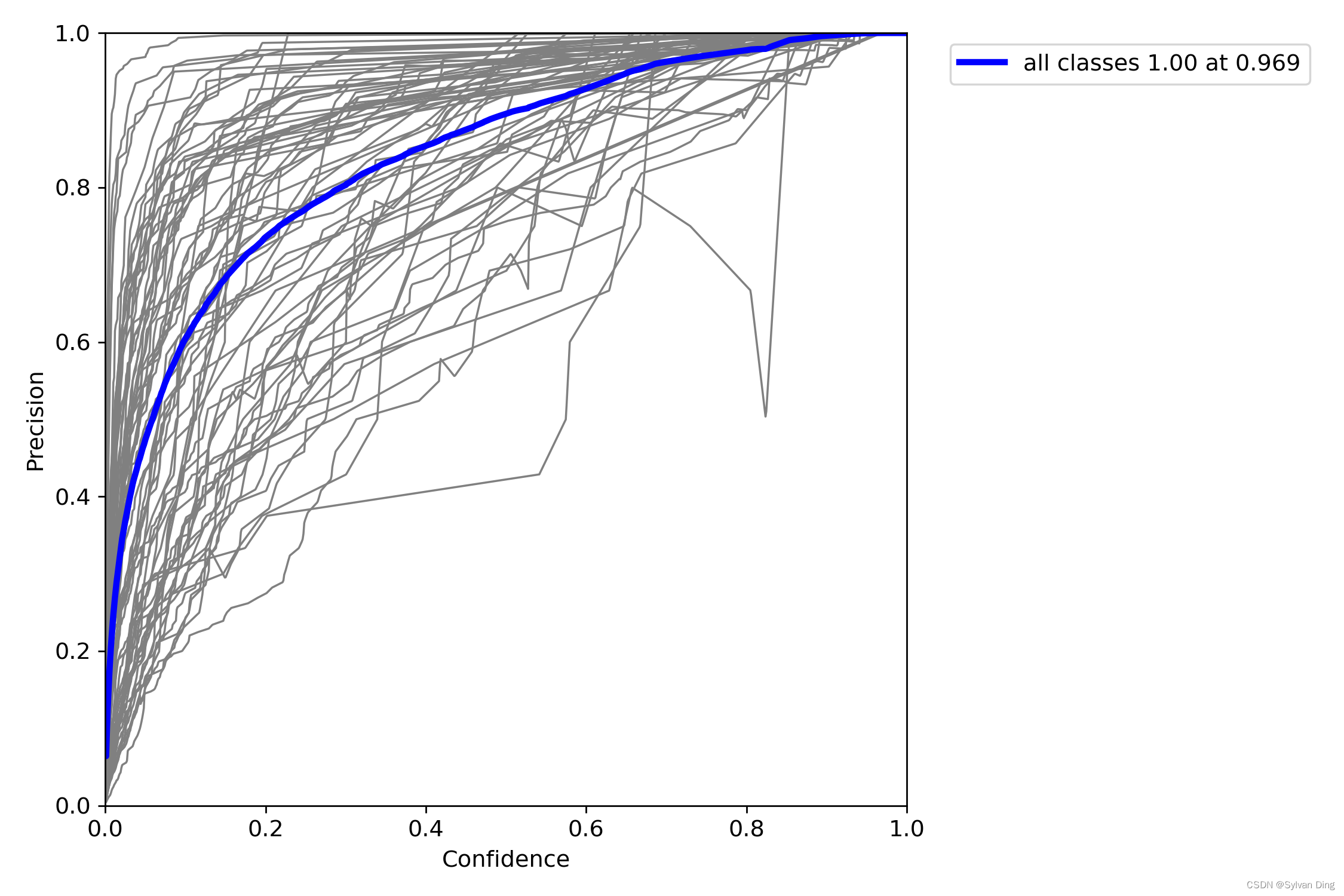
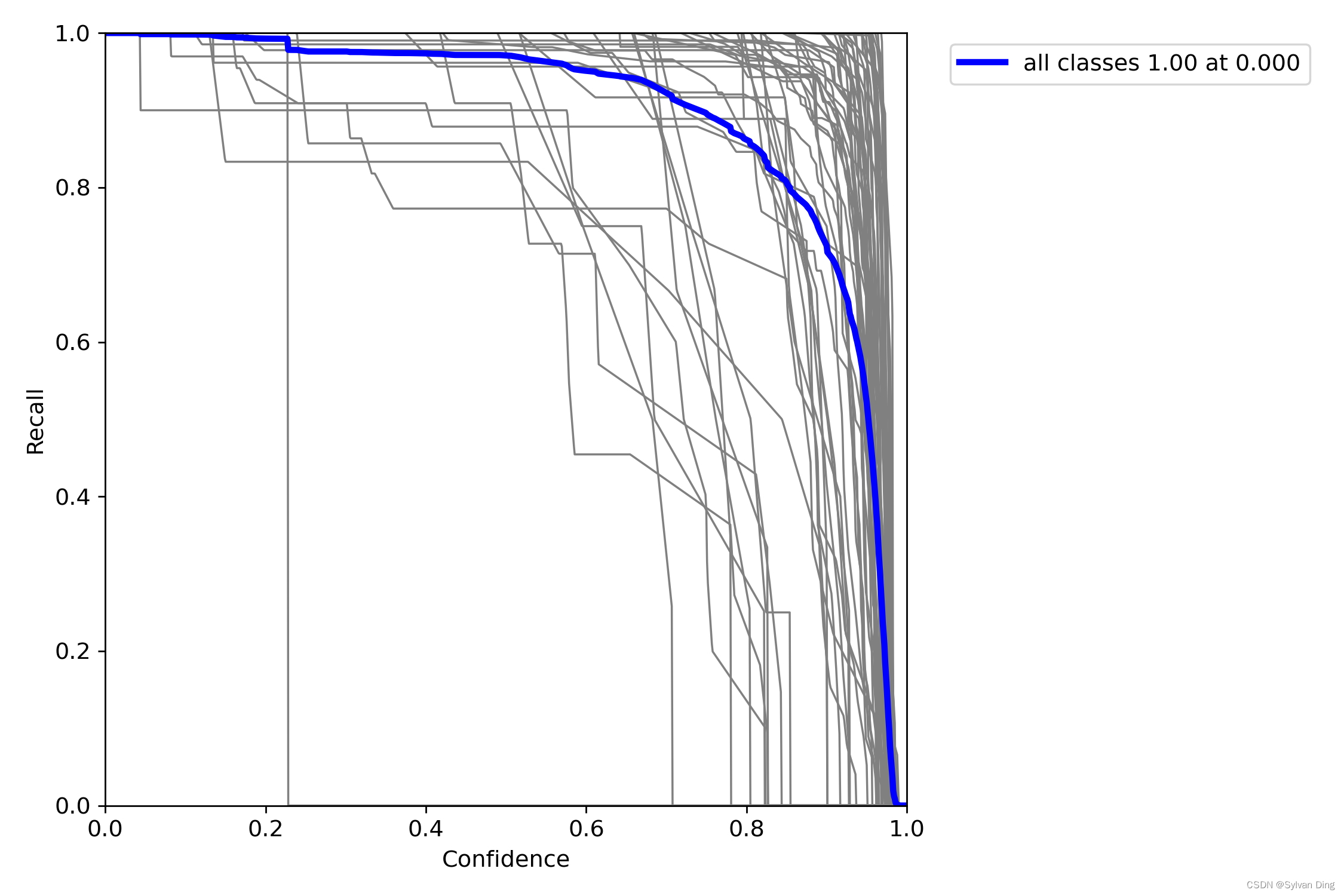
置信度和P、R的关系曲线
后期可依据该图,根据需要选取合适的置信度,调整菜品识别的精度和召回率。(精度和置信度成正比,而召回率和置信度成反比)
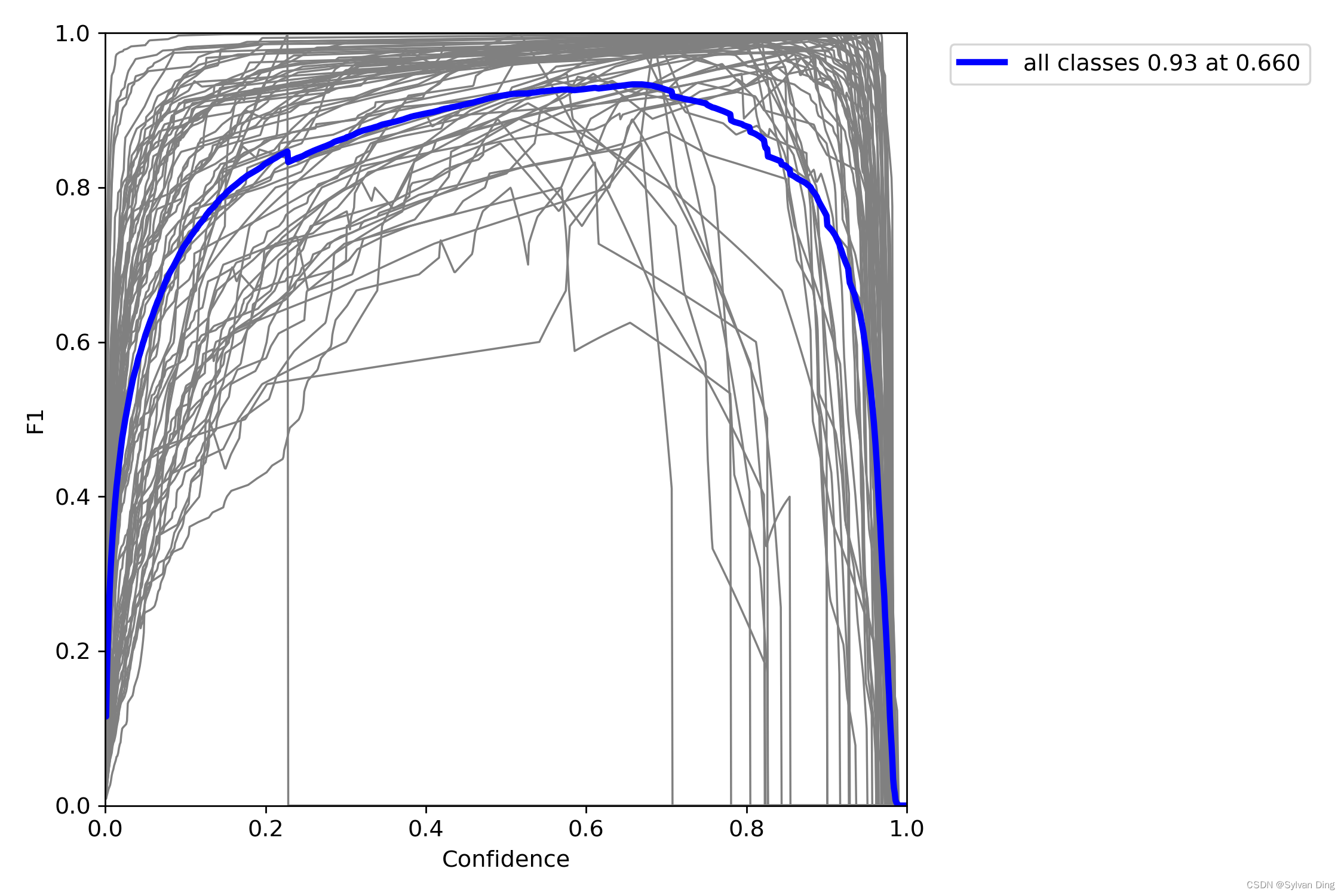
F1 Score
F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。 可以看到,当 Confidence 在 0.7 附近时,F1-Score 最优。
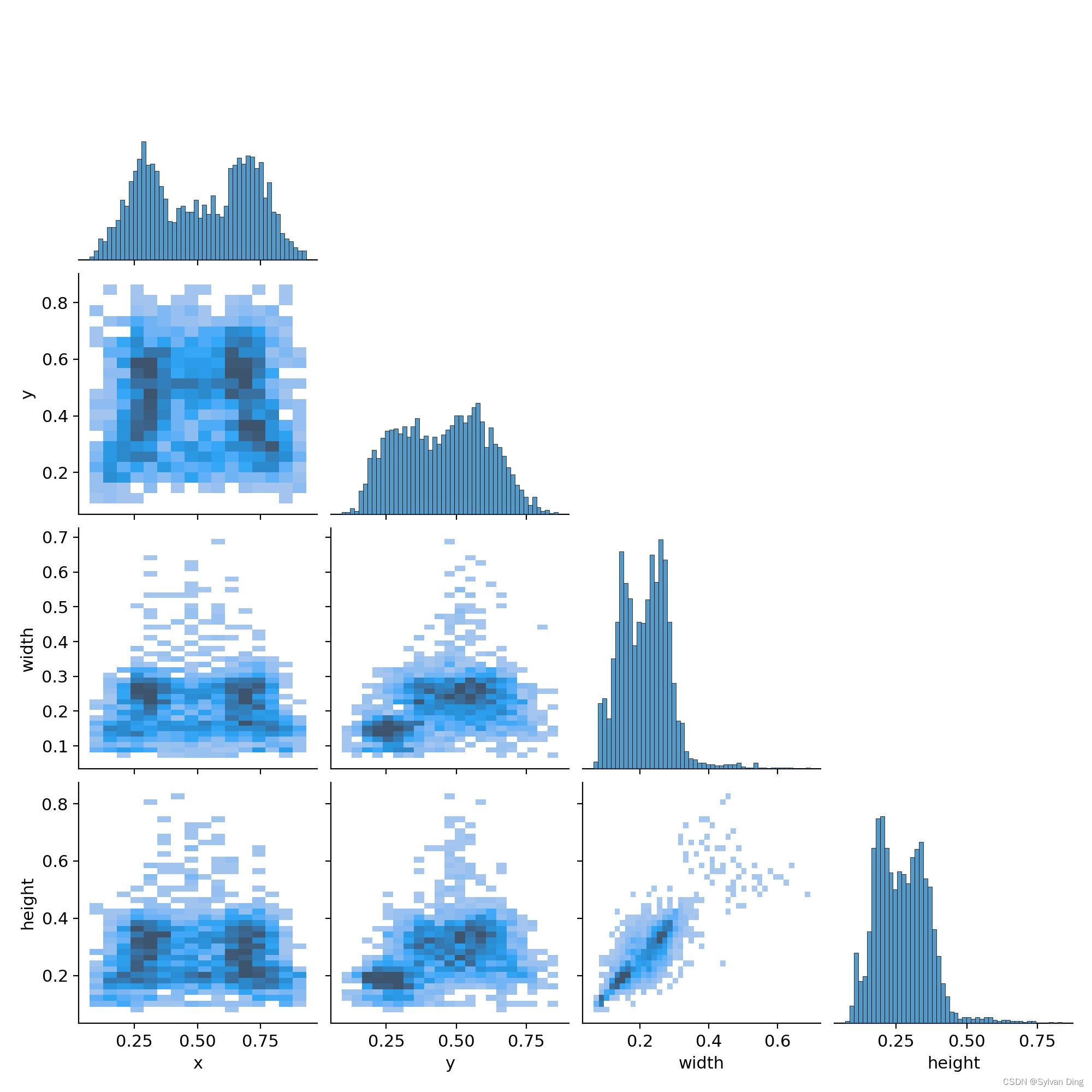
关于训练集中标签分布信息的描述
相关性直方图
[#5138] Correlogram is a group of 2d histograms showing each axis of your data against each other axis. The labels in your image are in xywh space.
很明显,width 和 height 成正相关分布;x 成双峰分布,意味着大多数人餐盘上食物是左边放一份、右边放一份的;height、width 都集中在 0.5 以下。相关性直方图也为后期 anchor 的选取提供了依据,为模型的进一步优化提供了参考。
分类直方图和标记框
显然,从 top-left 图可知,该样本的分类是有偏的,模型在某些小数量分类上的标签可能不优秀。
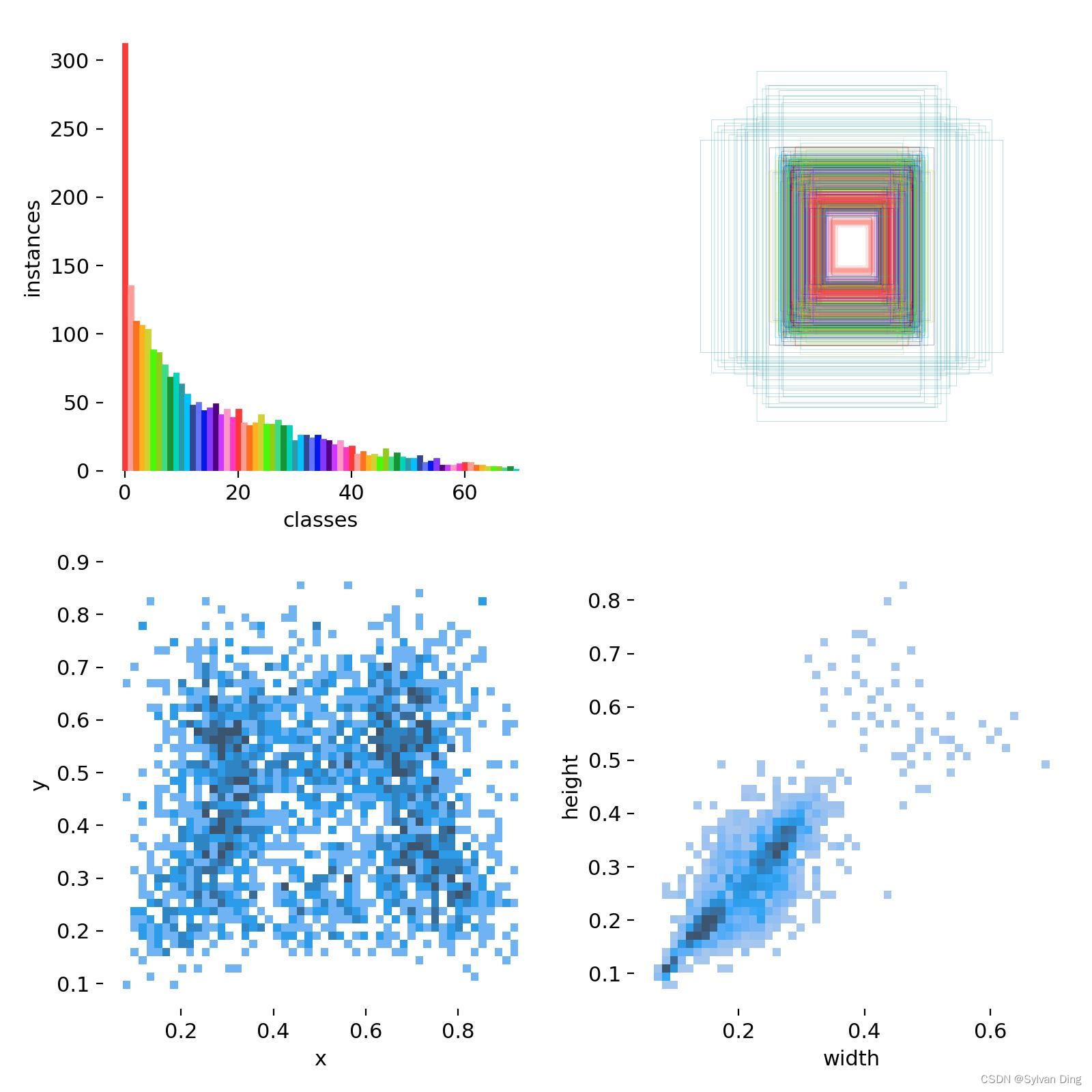
预测效果展示


项目亮点
? 贡献者:luo hua qin |ding ji xiang |chen qi fei | zhang yu han |cheng xi peng |jiang yu chen (2022.05.17)

提供软硬件一体化解决方案
金鹰智能结算系统为政企单位、医院食堂、学校食堂、民工工厂等不同单位提供智慧食堂软硬件一体化解决方案。智能结算台硬件端采用YOLOv5深度神经网络模型,识别速度快、精度高、可迁移学习,同时支持形式多种多样的支付方式,可实现刷脸支付、微信支付、支付宝支付和刷卡支付等,提高就餐效率。网页管理端可向食堂管理者提供财务报表,控制采购库存,降低运营成本。小程序可为顾客提供营养数据分析、菜品推荐、菜品营养信息查询和消费订单管理等功能服务。微信小程序还为管理者实现智能报表推送。帮助食堂摒弃传统运营弊端,满足不同客户在食堂运营中的全方位需求。
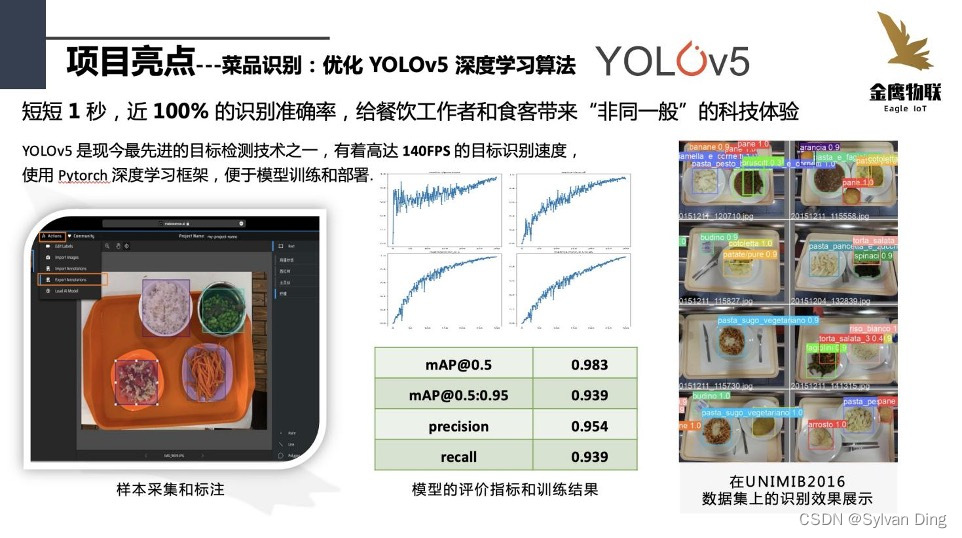
菜品识别:优化YOLOv5深度学习算法
金鹰智能结算系统使用开源的YOLOv5深度学习算法,针对不同食堂的应用场景对模型网络和参数进行改进,可以实现高达140 FPS的目标识别速度和近乎100%的识别准确度。YOLOv5基于Pytorch框架开发,能够轻松地将Pytorch权重文件转化为安卓使用的ONXX格式,或者通过CoreML转化为IOS格式,以便直接部署到Android应用端。
对于训练数据集过小问题,我们采用了平移、旋转、缩放、HSV、拼接等数据增强方法,这不仅增加了训练数据集的样本数量,还传送同等数量的样本情况下使样本特征的数量翻倍,缓解了每一次训练中送入到模型中的样本特征过少从而导致模型学习速度过慢的问题。
对于新增菜品,拟采用“迁移学习”的方法。考虑到大部分数据或任务是存在相关性的,不同应用场景大部分的菜品相似度非常高,所以可以通过迁移学习,可以将已经学到的模型参数通过新样本再次训练从而得到新模型,不用像大多数网络那样从零学习,这不仅加快模型的学习效率,还优化了模型效果。
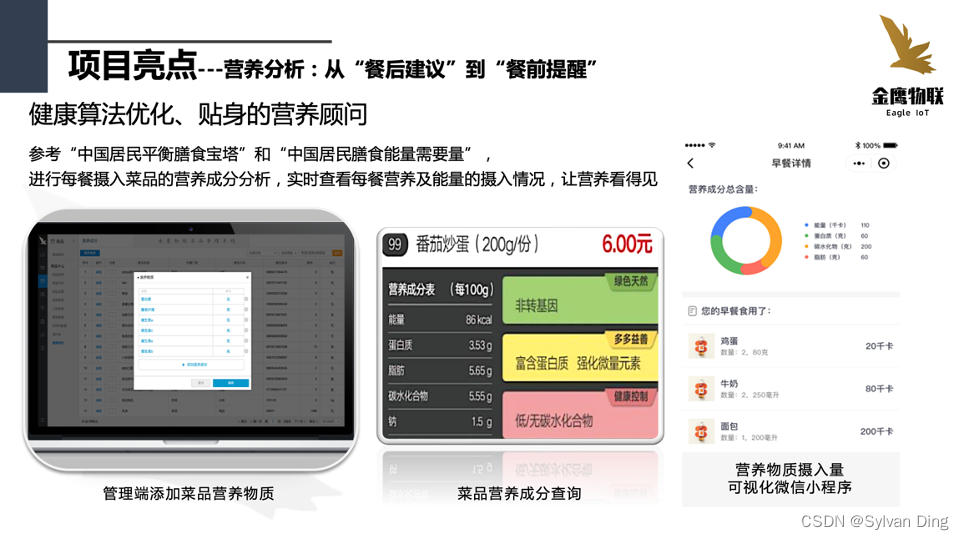
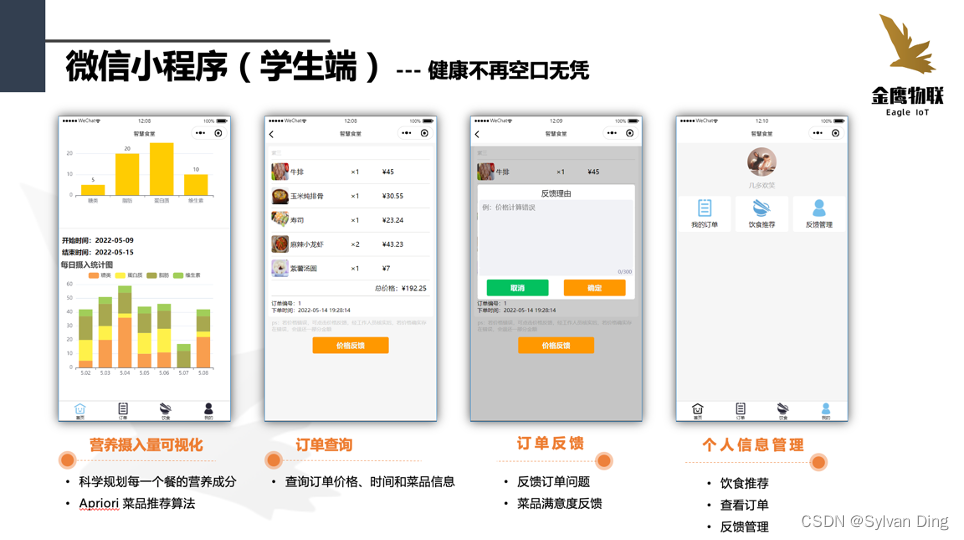
营养分析:从“餐后建议”到“餐前提醒”
“知己知彼,百战不殆”,健康的饮食生活需要人们了解自身的饮食情况,再根据健康的指标来改善饮食结构。金鹰智能结算系统通过小程序为顾客一系列的营养健康功能服务。小程序为顾客提供一周内详细的饮食数据分析,其中包括卡路里、蛋白质、脂肪、碳水化合物和维生素的摄入情况。为顾客了解自身的饮食情况提供了可视化的图表分析,方便顾客根据自己饮食营养分析结果来改善自己饮食结构。
为了使顾客能更健康更科学地改善自己的饮食结构,我们参考了“中国居民平衡膳食宝塔”和“中国居民膳食能量需要量”,为顾客提供一个合理的、科学的营养摄入水平指标。而且我们还为顾客提供菜品营养信息查询的功能服务,顾客可以随时随地在小程序内搜索查看菜品详细的营养信息,其中包括菜品的评价、卡路里含量、蛋白质含量、脂肪含量以及碳水化合物含量等,为顾客改善自己的饮食结构提供更详细的参考信息。
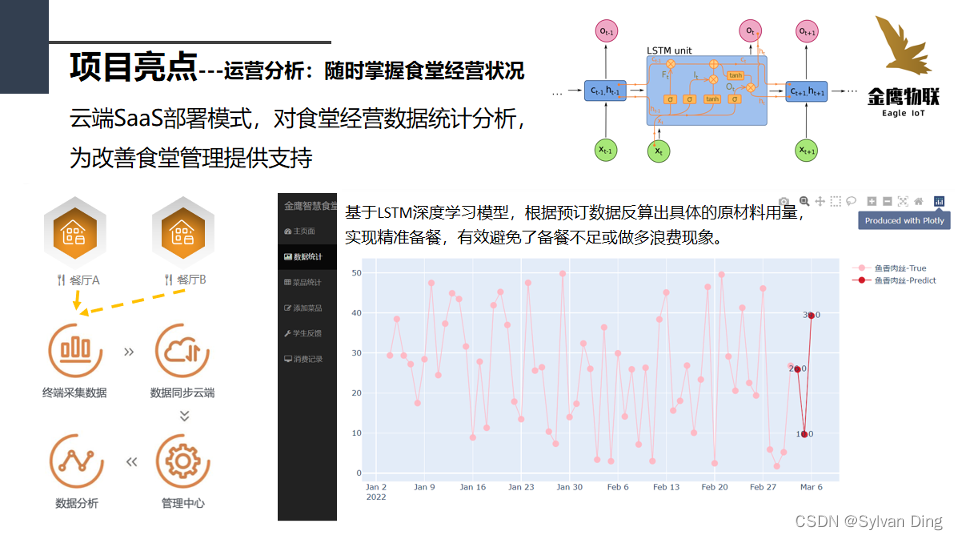
运营分析:随时掌握食堂经营状况
食堂的菜品供应量与顾客消费满意度和食堂的盈利息息相关。食堂的当天菜品供应量不足不仅会降低消费满意度,还会使食堂错失大量的销售机会,不利于营业额的增长。食堂的当天菜品供应量过大也会导致食材的严重浪费,不得不以饲料低价出售到养殖场,降低了利润。
金鹰智能结算系统使用LSTM时间序列预测模型,结合一段时间内的菜品销量情况,为食堂管理者提供每一个菜品的下一次的销量情况,从而为食堂下一次的食材进销量合理取值提供参考,有效地降低食堂的菜品供应量过高或者过少的发生概率,使食堂利润化最大化。
菜品推荐
金鹰智能结算系统根据顾客一段时间内的饮食数据,通过小程序为顾客提供菜品推荐的功能服务。菜品推荐是结合顾客身体健康指标和饮食习惯,通过大数据分析和数据挖掘Apriori算法,为顾客推荐有利于顾客健康的、和顾客口味相似的菜品。这有利于提升顾客的消费满意度,增加顾客粘性度。
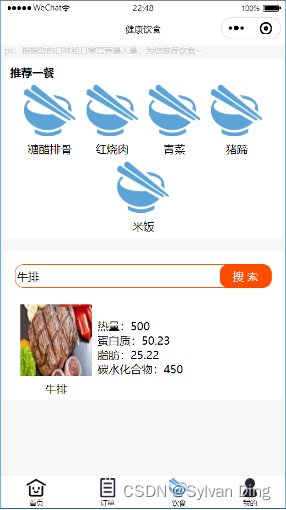
整体方案框架
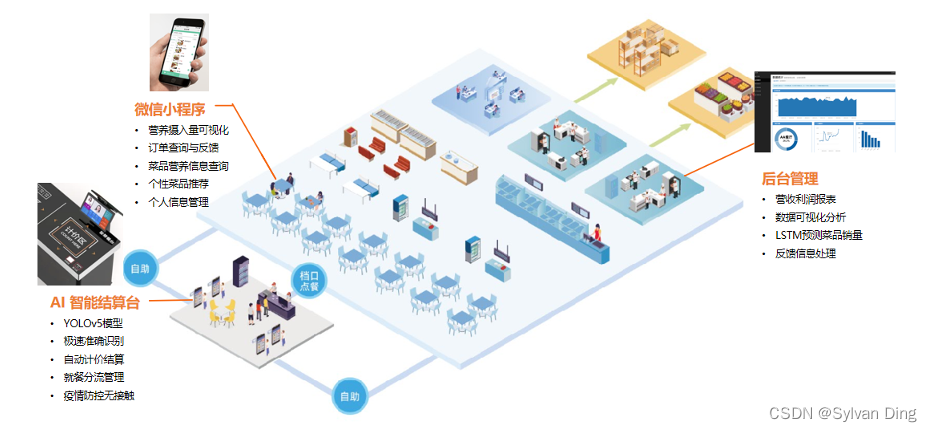
本产品面向高校食堂,研发拥有菜品识别、智能结算、菜品推荐、健康饮食、订单管理、后台管理等功能模块的一系列软硬件产品,提供从菜品识别到智能结算再到健康饮食管理一体化的功能服务。
1、智能识别结算台
基于YOLOv5目标检测模型算法,拥有菜品识别和智能结算功能一体化的智能识别机器,主要提供给各高校食堂使用。
2、微信小程序
基于大数据分析与数据挖掘Apriori算法,拥有健康饮食管理、菜品推荐、订单管理、菜品营养信息查询等功能模块,主要提供给顾客使用。
3、WEB后台管理
基于Web开发与数据可视化、数据挖掘技术,拥有订单流水账信息可视化、订单管理、菜品销量预测等功能服务,主要提供给高校食堂管理者使用。
智能识别机器、微信小程序和WEB后台管理三个软件硬件组成一个完整的智能食堂结算系统。该系统还应该实现食品安全溯源、能够在多种餐饮场景上进行部署等功能。
系统流程如下图所示,我们会在食堂中部署多台“智能结算台”设备,同时设置一位“督导员”,“督导员”负责监督学生操作设备,防止发生“逃单”现象。当顾客到达食堂并选取菜品后,将餐盘放到我们制作的智能结算台上,结算台会根据深度学习算法识别出餐盘中的菜品并计算价格,之后结算台在展示屏上显示菜品的相关信息并给出付款方式:微信扫码支付/支付宝扫码支付/刷脸支付/校园卡支付,顾客可选择任意一种支付方式进行支付。以微信扫码支付为例,扫码完成后,会跳转到我们开发的微信小程序中进行支付,支付成功后生成订单数据。在小程序中,顾客可查看每日热量、卡路里的摄入量等信息,也可针对存在问题的订单进行意见反馈。同时,后台会实时展示这些交易记录,定期生成销售报告给食堂管理者,协助管理者分析数据,实现精准备餐、减少库存的浪费。
智慧食堂系统的工作流程:
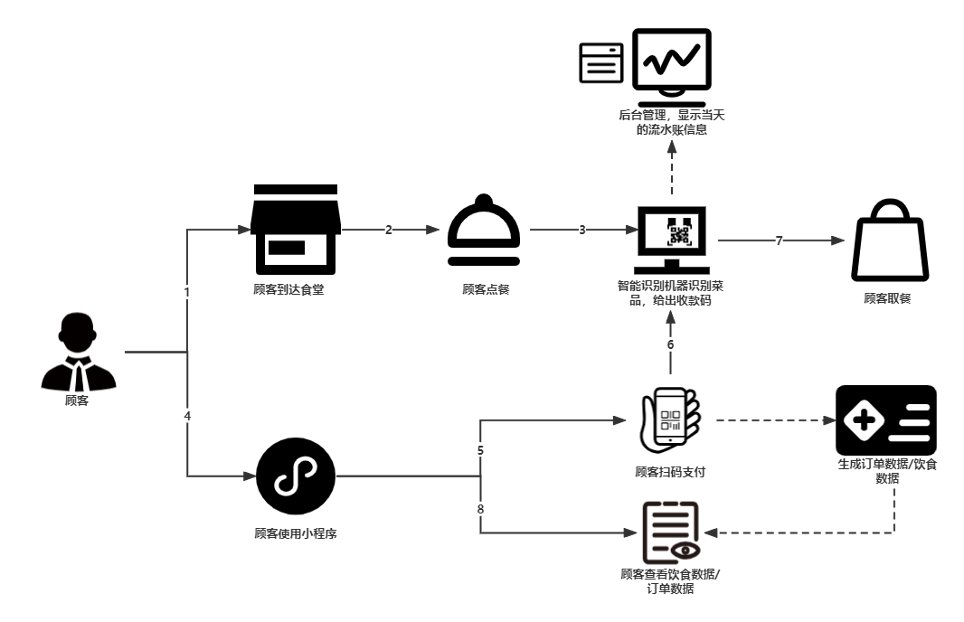
智能结算台
技术框架
智能结算台整体使用了LNMJ(Linux、Nginx、MySQL、Java)架构(Nginx相对Apache可以进行多路复用,性能更高)。
对于识别菜品和支付业务,算法识别给出菜单和价格等信息后向Nginx服务器发起生成订单的请求,后端根据订单金额生成预付单数据返回给前端页面,同时将预付单数据保存至MySQL相应表单中,支付状态设置为待支付。然后摄像头扫描用户的付款码后将数据发送到Nginx,Nginx向微信支付API发起支付请求,微信支付后台系统收到支付请求,根据验证密码规则判断是否验证用户的支付密码,不需要验证密码的交易直接发起扣款,需要验证密码的交易会弹出密码输入框。支付成功后微信端会弹出成功页面,同时向Nginx后台返回支付结果,Nginx接收到支付结果后将对应订单的支付状态设为完成,同时向前端返回支付成功的信号,前端报送支付成功的信号后进入下一轮识别状态。
对于小程序端的查询、反馈等业务,同样通过Nginx后端处理相应的逻辑对数据库进行增删改查等操作,拿到数据后小程序前端渲染展现给用户。
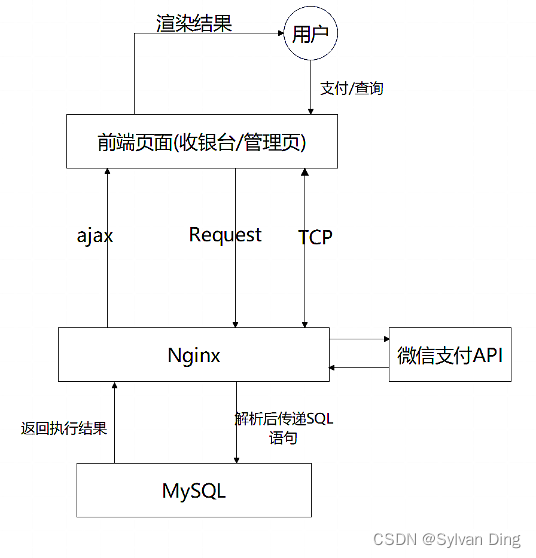
详细功能
金鹰物联智能结算台为广大学生提供了极速便捷的结算渠道,只需要将托盘放入指定区域,结算台就能够在1秒内识别菜品,支持微信、支付宝和人脸识别支付,体验无感便利的快捷支付。机器具有快、易、稳的优点,快:一秒识别极速支付;易:一天即可部署上线,无需老板亲自动手;稳:算法优秀识别率稳定可靠,多种支付渠道任您挑选!

微信小程序
前景上,依托于微信这个超级APP的巨大流量池,使得小程序在渗透率和粘性方面都表现极佳,在小程序的月活跃用户数上,从2019年6月统计的7.43亿增长到2020年6月的8.29亿,占所有微信用户的86.9%,并且根据腾讯公布的数据显示,2021年微信月活跃用户数量已经达到12.682亿,即小程序用户数会随着微信用户的继续增多而稳定增长。从用户使用的小程序类型上来看,在2021年末统计的小程序活跃排行榜前100名中,电子商务、美食外卖、旅游出行、便携生活和游戏服务类这五类共占据了73席,越来越多的人选择使用小程序来满足自己的日常需求。
本项目面向用户开发微信小程序,为用户提供一个数据查看、分析和反馈的平台,小程序作为一种轻量型的应用,相较于手机APP,其最大的优点就是即开即用,不再需要下载和安装的过程,并且依托于微信平台,小程序也可以很方便地进行消息的提醒和推送。
技术上,小程序后台代码整体的开发由Java来开发,Java作为当代互联网首屈一指的开发语言,有着众多强大的、稳定的开源软件简化软件开发,spring、springMVC、mybatis框架作为前几年主流的框架,可以说给web开发带来了前所未有的便捷。版本依赖管理由maven统一处理,maven和gradle作为当代主流的版本控制管理工具,不仅让程序的依赖拥有统一的配置,更主要的是让团队开发起来更加容易。数据库选用mysql,在这个大数据时代,数据库的选型尤为重要,mysql作为当代最主流的关系型数据库,可以满足我们日常的业务开发,还提供了主从复制,确保数据的安全性,超高的性能也为我们的开发提供了很大的便捷。
WEB管理端
技术框架
通过Vue进行前端页面的展示。Vue是一套用于构建用户界面的渐进式框架。Vue作为前端框架的特点有:
- 构建用户界面,只需要关系view层
- 轻量快速
- Vue是渐进式框架,因其具有声明式渲染、组件系统、客户端路由、构建工具的功能,对于开发很友好。
与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,其采用了MVVM的开发思想,MVVM是前端视图层的分层开发思想,主要把每个页面,分成了MV和VM。前端MVVM的思想是为了让我们开发更加方便,因为MVVM提供了数据的双向绑定,数据的双向绑定时由MV提供的并且其与ECharts的结合性很强,方便进行数据可视化的展示。
Vue与其他框架不同的点在于其DOM的刷新是响应式的,在非第一次渲染的时候,Vue会最大限度地复用已创建的DOM元素,故而负荷会较小,速度较快。
相应的后端使用的是Flask,通过Flask与MySQL进行数据库的增删改查并提供前端的接口。Flask是一个Web框架,属于微框架,框架很轻量,更新依赖小,在本项目对于后端要求不大的情况下很适用。
详细功能
【多维度管理】
从营收利润、客流单价、菜品销量、受欢迎程度等多个维度呈现食堂的运营状况。为管理者决策分析提供可靠的数据支持。
【智能化营销管理】
可将账单核对、消费策略设置等多种业务流程智能化,通过便捷化、简单化的操作,取代大量的人力投入。
【实时数据分析管理】
融合零售常用数据分析方法和数据建模,将数据变为具有价值的参考对象,为经营者制定运营策略和营销方案提供参考。
【数据可视化管理】
将不直观的数据转化为可视化的图表,为管理者提供直观、准确的数据分析结果。
【智能预测管理】
运用深度学习、LSTM时间序列预测模型等技术,分析菜品在某段时间内的销售情况,用户复购情况。进行预测分析,预测菜品在未来的销售情况,为管理者进行菜品的增加和改进提供参考。

总结和展望
食品图像识别在计算机视觉和多媒体等研究领域中具有重要的理论意义和实际应用价值,但目前仍存在诸多问题与挑战。本文基于YOLOv5v6.1提出了一套适用于中式快餐店的菜品识别自助支付系统,综述了食品识别领域的发展现状,简要介绍了YOLOv5模型的历史背景、发展优势和网络结构。在数据集预处理过程中,通过解析UNIMIB2016,构建了一套行之有效的标签格式转换与校验流程,解决了YOLOv5中文件路径问题、标签格式转换问题和因EXIF信息的存在而导致的标记错位问题。在模型训练阶段,配置了云服务器,引入了Weights and Bias可视化工具,实现了在线监督训练和sweep超参数调优的功能,在sweep中使用hyperband剪枝算法加速了sweep过程,并给出了对于训练过程中可能出现的问题的解决方法。最后介绍了目标识别领域的评价指标和YOLOv5的损失函数,分析了sweep超参数调优的结果,选取最优参数组合训练模型,通过分析样本分布、PR曲线等,选取最佳预测置信度,大幅提升了预测精度和召回率,部署了模型并制作了客户端。
本文虽然选取了一组相对优秀的参数组合以提升模型的mAP@0.5等评价指标,但是并没有针对目标数据集对模型进行优化,比如微调网络结构以提升精度和速度、使用图像加权策略以缓解样本不平衡问题、使用矩阵推理训练模型以加快推理过程并减少冗余信息、改进k-means以聚类生成anchor、对标签进行平滑处理以增强模型的鲁棒性、冻结backbone以便在数据量不足时获得较好的特征提取效果并提升训练速度。
通过本次实验,对YOLOv5模型训练提出了一些改进方法,认识到了现存的技术难题,为后续项目落地打下基础,也证明了项目落地在技术层面上的可行性。
导师评价
指导教师意见
“人工智能+物联网”(AIoT)已经成为新时代产品的新模式。本项目组采用人工智能中的深度学习模型对菜品进行识别,识别速度快、准确率高;使用物联网技术开发了菜品识别的相关硬件设施;搭建了后端管理网页,为食堂管理者提供实时数据可视化工具;使用大数据分析技术进行数据可视化,为用户提供饮食数据可视化应用,以此为基础开发了微信小程序;使用数据挖掘技术对用户饮食习惯的进行数据挖掘,实现菜品推荐功能。本项目形成了一条从提供菜品的智能识别到健康餐饮服务的完整的产品服务链,在产品定位、商业模式、营销渠道等方便做了现实可行的之行方案,符合创新创业思维。因产品的前沿性、实用性、生动性,相信这款作品能吸引用户的眼球,在互联网中得到迅速传播,获得分裂式成长。小组关心社会现状,加之敏锐的洞察力,及时把握了市场需求,此外,团队动手协作能力和明确的分工也值得赞赏。此作品具有很好社会价值和经济价值以及技术价值。
企业导师意见
“人工智能+物联网”作为新时代新技术的风口,为新产品结合新技术研发提供新的思路。本项目抓住高校食堂群体,精准解决用户痛点,潜在市场价值巨大。项目以人工智能技术作为技术壁垒,恰如其分的打造了智慧食堂的生态体系,体现了华侨大学鼓励学生创新创业、把学科知识转换成应生产应用的优秀培养模式。本项目同时拥有自己商业模式思路以及盈利点和技术创新点。此作品具有很好社会价值与市场价值以及技术价值,故此推荐。
❤️ 金鹰物联智慧食堂项目组原创文章,转载请注明出处!©️ SylvanDing’s Blog
⭐️ 金鹰物联智慧食堂项目官网(beta0.1):http://food-detect.sylvanding.online
参考文献
- YOLOv5 Documentation, https://docs.ultralytics.com/tutorials/train-custom-datasets/
- Matlab containers.Map, https://www.mathworks.com/help/matlab/ref/containers.map.html
- SCIPY Documentation, https://docs.scipy.org/doc/scipy/reference/generated/scipy.io.loadmat.html
- Food recognition: a new dataset, experiments and results (Gianluigi Ciocca, Paolo Napoletano, Raimondo Schettini) In IEEE Journal of Biomedical and Health Informatics, volume 21, number 3, pp. 588-598, IEEE, 2017.
- Aguilar E, Remeseiro B, Bolaños M, et al. Grab, pay, and eat: Semantic food detection for smart restaurants[J]. IEEE Transactions on Multimedia, 2018, 20(12): 3266-3275.
- 闵巍庆,刘林虎,刘宇昕,罗梦江,蒋树强.食品图像识别方法综述[J].计算机学报,2022,45(03):542-566.
- 董天骄. 基于卷积神经网络的饮食分类与识别[D]. 杭州电子科技大学, 2018.
- 李成. 基于改进YOLOv5的小目标检测算法研究[J]. 长江信息通信,2021,34(9):30-33. DOI:10.3969/j.issn.1673-1131.2021.09.010.
- 琚恭伟,焦慧敏,张佳明,等. 基于YOLOv5的医用外科手套左右手识别[J]. 制造业自动化,2021,43(12):189-192. DOI:10.3969/j.issn.1009-0134.2021.12.046.
- 赵睿,刘辉,刘沛霖,雷音,李达.基于改进YOLOv5s的安全帽检测算法[J/OL].北京航空航天大学学报:1-16[2022-05-01].DOI:10.13700/j.bh.1001-5965.2021.0595.
- 马琳琳,马建新,韩佳芳,李雅迪.基于YOLOv5s目标检测算法的研究[J].电脑知识与技术,2021,17(23):100-103.DOI:10.14004/j.cnki.ckt.2021.2402.
- 邱锡鹏, 神经网络与深度学习, 机械工业出版社, https://nndl.github.io, 2020.
- Yolov5 系列1— Yolo发展史以及Yolov5模型详解, https://samuel92.blog.csdn.net/article/details/108845799
- Yolov5目标检测训练模型学习总结, https://www.cnblogs.com/isLinXu/p/15170963.html
- 【目标检测】yoloV5算法详解, https://blog.csdn.net/qq_40373651/article/details/121501699
- Weights & Biases Documentation, https://docs.wandb.ai
- 机器学习超参数优化算法-Hyperband, https://www.cnblogs.com/marsggbo/p/10161605.html
- 深度学习中的数据增强方法都有哪些, https://zhuanlan.zhihu.com/p/61759947
- 在ubuntu上安装Python有两种方法, https://www.cnblogs.com/yjp372928571/p/12758564.html
- 使用混淆矩阵分析目标检测, https://zhuanlan.zhihu.com/p/443499860
- 目标检测中的AP、mAP, https://zhuanlan.zhihu.com/p/88896868
- 如何衡量目标检测模型的优劣, https://zhuanlan.zhihu.com/p/422645189
- 计算机视觉中评价指标计算, https://blog.csdn.net/l1076604169/article/details/100731210
- yolov5目标检测神经网络——损失函数计算原理, https://zhuanlan.zhihu.com/p/458597638
- 目标检测Anchor是什么?如何科学设置, https://zhuanlan.zhihu.com/p/112574936
- PyQt5 5.15.6, https://pypi.org/project/PyQt5
- 手把手带你调参Yolo v5 (v6.1)

